序列化与反序列化
为什么要序列化
内存中的map、slice、array以及各种对象,如何保存到一个文件中? 如果是自己定义的结构体的实例,如何保存到一个文件中?
如何从文件中读取数据,并让它们在内存中再次恢复成自己对应的类型的实例?
要设计一套协议,按照某种规则,把内存中数据保存到文件中。文件是一个字节序列,所以必须把数据转换成字节序列,输出到文件。这就是序列化。 反之,从文件的字节序列恢复到内存并且还是原来的类型,就是反序列化。
定义
serialization 序列化:将内存中对象存储下来,把它变成一个个字节。转为 二进制 数据
deserialization 反序列化:将文件的一个个字节恢复成内存中对象。从 二进制 数据中恢复 序列化保存到文件就是持久化。
可以将数据序列化后持久化,或者网络传输;也可以将从文件中或者网络接收到的字节序列反序列化。
我们可以把数据和二进制序列之间的相互转换称为二进制序列化、反序列化,把数据和字符序列之间的 相互转换称为字符序列化、反序列化。
json 是字符序列化!
字符序列化:JSON、XML等
二进制序列化:Protocol Buffers、MessagePack等
JSON
JSON(JavaScript Object Notation, JS 对象标记) 是一种轻量级的数据交换格式。它基于1999年发布的 ES3 (ECMAScript是w3c组织制定的JavaScript规范)的一个子集,采用完全独立于编程语言的文本格 式来存储和表示数据。应该说,目前JSON得到几乎所有浏览器的支持。参看http://json.org
JSON的数据类型
值
双引号引起来的字符串、数值、true和false、null、对象、数组,这些都是值
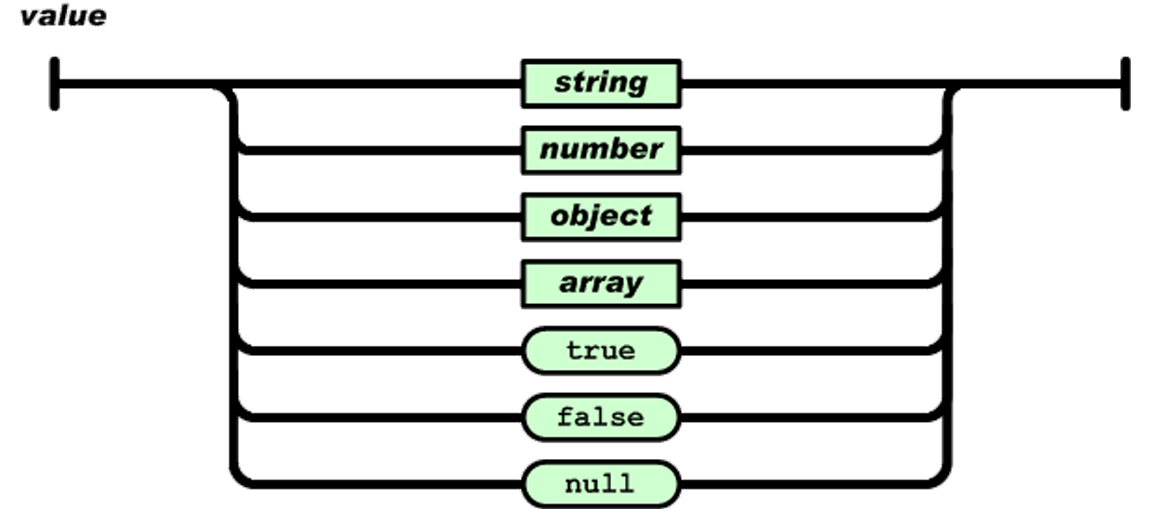
字符串
由双引号包围起来的任意字符的组合,可以有转义字符
数值
有正负,有整数、浮点数。
对象
无序的键值对的集合 格式: {key1:value1, … ,keyn:valulen} key必须是一个字符串,需要双引号包围这 个字符串。 value可以是任意合法的值。
{
"key":value
"k1":v1
...
}
数组
有序的值的集合 格式:[val1,…,valn]

{
[
v1,
v2,
v3
]
}
{
"person": [
{
"name": "tom",
"age": 18
},
{
"name": "jerry",
"age": 16
}
],
"total": 2
}
特别注意:JSON是字符串,是文本。 JavaScript引擎可以将这种字符串解析为某类型的数据。
json 包
Go标准库中提供了encoding/json包,内部使用了反射技术,效率较为低下。参看 https://go.dev/blog/json
- json.Marshal(v any) ([]byte, error),将v序列化成字符序列(本质上也是字节序列),这个过程称为Encode
- json.Unmarshal(data []byte, v any) error,将字符序列data反序列化为v,这个过程称为Decode
基本类型序列化
package main
import (
"encoding/base64"
"encoding/json"
"fmt"
"github.com/vmihailenco/msgpack/v5"
)
func f_1_2() {
var data = []any{
100, 2.5, true, false, nil, "accc",
// []interface ; go 害怕里面有其他数据类型,所有为interface
[...]int{97, 98, 99}, // go array ==> json string parse js array
map[string]int{"aaa": 1111, "bbb": 2222},
}
fmt.Println(data)
// serialize
var target = make([][]byte, len(data))
for i, v := range data {
b, err := json.Marshal(v) // []byte
if err != nil {
continue
}
target = append(target, b)
fmt.Printf("%d : %T %[2]v %T %[3]v ,%s \n", i, v, b, string(b))
}
t, _ := fmt.Println(json.Marshal(data)) // 对切片整体序列化 -----> []byte string
fmt.Printf("%q \n", t) // string类型
fmt.Println(target) // 切片类型
// 反序列化
for i, v := range target {
var j any
err := json.Unmarshal(v, &j) // j的值便是反序列化的值
if err != nil {
continue
}
fmt.Printf("%d : %T %[2]v,%T %[3]v \n", i, v, j)
}
}
func main(){
f_1_2()
}
运行结果如下
[100 2.5 true false <nil> accc [97 98 99] map[aaa:1111 bbb:2222]]
0 : int 100 []uint8 [49 48 48] ,100
1 : float64 2.5 []uint8 [50 46 53] ,2.5
2 : bool true []uint8 [116 114 117 101] ,true
3 : bool false []uint8 [102 97 108 115 101] ,false
4 : <nil> <nil> []uint8 [110 117 108 108] ,null
5 : string accc []uint8 [34 97 99 99 99 34] ,"accc"
6 : [3]int [97 98 99] []uint8 [91 57 55 44 57 56 44 57 57 93] ,[97,98,99]
7 : map[string]int map[aaa:1111 bbb:2222] []uint8 [123 34 97 97 97 34 58 49 49 49 49 44 34 98 98 98 34 58 50 50 50 50 125] ,{"aaa":1111,"bbb":2222}
[91 49 48 48 44 50 46 53 44 116 114 117 101 44 102 97 108 115 101 44 110 117 108 108 44 34 97 99 99 99 34 44 91 57 55 44 57 56 44 57 57 93 44 123 34 97 97 97 34 58 49 49 49 49 44 34 98 98 98 34 58 50 50 50 50 125 93] <nil>
'ß'
[[] [] [] [] [] [] [] [] [49 48 48] [50 46 53] [116 114 117 101] [102 97 108 115 101] [110 117 108 108] [34 97 99 99 99 34] [91 57 55 44 57 56 44 57 57 93] [123 34 97 97 97 34 58 49 49 49 49 44 34 98 98 98 34 58 50 50 50 50 125]]
8 : []uint8 [49 48 48],float64 100
9 : []uint8 [50 46 53],float64 2.5
10 : []uint8 [116 114 117 101],bool true
11 : []uint8 [102 97 108 115 101],bool false
12 : []uint8 [110 117 108 108],<nil> <nil>
13 : []uint8 [34 97 99 99 99 34],string accc
14 : []uint8 [91 57 55 44 57 56 44 57 57 93],[]interface {} [97 98 99]
15 : []uint8 [123 34 97 97 97 34 58 49 49 49 49 44 34 98 98 98 34 58 50 50 50 50 125],map[string]interface {} map[aaa:1111 bbb:2222]
结构体序列化
package main
import (
"encoding/base64"
"encoding/json"
"fmt"
"github.com/vmihailenco/msgpack/v5"
)
type Person struct {
Name string `json:"nn" msgpack:"name"` // 字段,``序列化后的名称
Age int `json:"age,omitempty"` // 字段中要紧挨着写,omitempty 忽略空值
}
func f_1_3() {
var data = Person{"Tom", 24}
// 序列化
b, err := json.Marshal(data)
if err != nil {
panic(err)
}
// {"nn":"Tom","Age":24}
fmt.Printf("%T %+[1]v; %T %[2]v \n", data, b)
fmt.Println(string(b)) // 这个对象的类型是什么? ===> 损失了,因为js没有Person类型,主体的数据类型没丢
fmt.Println("___________________________")
// 反序列化
var p1 Person
// 1. 我知道目标类型
err = json.Unmarshal(b, &p1)
if err != nil {
panic(err)
}
fmt.Printf("%T %+[1]v \n", p1)
// 2.我不知道你是什么类型
var i interface{}
err = json.Unmarshal(b, &i)
if err != nil {
panic(err)
}
fmt.Printf("%T %+[1]v \n", i) // T 是什么类型 ===> interface map key-value对
}
func main(){
f_1_3()
}
切片序列化
package main
import (
"encoding/base64"
"encoding/json"
"fmt"
"github.com/vmihailenco/msgpack/v5"
)
type Person struct {
Name string `json:"nn" msgpack:"name"` // 字段,``序列化后的名称
Age int `json:"age,omitempty"` // 字段中要紧挨着写,omitempty 忽略空值
}
// 切片
func f_1_6() {
// 序列化
var data = []Person{
{Name: "AAA", Age: 20},
{Name: "aaa", Age: 32},
}
b, err := json.Marshal(data)
if err != nil {
panic(err)
}
fmt.Println(b, string(b)) // 请问序列化后的字符串中,还有类型吗?有什么?
// 反序列化
// 不知道类型
var i interface{}
err = json.Unmarshal(b, &i)
if err != nil {
panic(err)
}
fmt.Printf("%T: %+[1]v\n", i)
// i类型为[]interface{},值为[map[Age:20 Name:AAA] map[Age:32 Name:aaa]]
// 知道目标类型
var b1 = []byte(`[{"name":"AAA","Age":20},{"name":"aaa","Age":32}]`)
var j []Person
err = json.Unmarshal(b1, &j)
if err != nil {
panic(err)
}
fmt.Printf("%T: %+[1]v\n", j)
// j类型为[]Person,值为[{Name:AAA Age:20} {Name:aaa Age:32}]
}
运行结果
[91 123 34 110 110 34 58 34 65 65 65 34 44 34 97 103 101 34 58 50 48 125 44 123 34 110 110 34 58 34 97 97 97 34 44 34 97 103 101 34 58 51 50 125 93] [{"nn":"AAA","age":20},{"nn":"aaa","age":32}]
[]interface {}: [map[age:20 nn:AAA] map[age:32 nn:aaa]]
[]main.Person: [{Name: Age:20} {Name: Age:32}]
字段标签
结构体的字段可以增加标签tag,序列化、反序列化时使用
- 在字段类型后,可以跟反引号引起来的一个标签,用json为key,value用双引号引起来写,key与 value直接使用冒号,这个标签中不要加入多余空格,否则语法错误
- Name string
json:"name",这个例子序列化后得到的属性名为name- json表示json库使用
- 双引号内第一个参数用来指定字段转换使用的名称,多个参数使用逗号隔开
- Name string
json:"name,omitempty",omitempty为序列化时忽略空值,也就是该字段 不序列化- 空值为false、0、空数组、空切片、空map、空串、nil空指针、nil接口值
- 空数组、空切片、空串、空map,长度len为0,也就是容器没有元素
- Name string
- 如果使用
-,该字段将被忽略- Name string
json:"-",序列化后没有该字段,反序列化也不会转换该字段 - Name string
json:"-,",序列化后该字段显示但名为"-"
- Name string
- 多标签使用空格间隔
- Name string
json:"name,omitempty" msgpack:"myname"
- Name string
JSON序列化的Go实现效率较低,由此社区和某些公司提供大量开源的实现,例如easyjson、jsoniter、 sonic等。对于各个Json序列化包的性能对比这里不列出来了,有兴趣的同学自己查看。基本使用方式兼 容官方实现。
MessagePack
MessagePack是一个基于二进制高效的对象序列化类库,可用于跨语言通信。 它可以像JSON那样,在 许多种语言之间交换结构对象。但是它比JSON更快速也更轻巧。 支持Python、Ruby、Java、C/C++、 Go等众多语言。宣称比Google Protocol Buffers还要快4倍。
文档 MessagePack encoding for Go (uptrace.dev)
安装
go get github.com/vmihailenco/msgpack/v5
基本使用方法和json包类似
package main
import (
"encoding/base64"
"encoding/json"
"fmt"
"github.com/vmihailenco/msgpack/v5"
)
type Person struct {
Name string `json:"nn" msgpack:"name"` // 字段,``序列化后的名称
Age int `json:"age,omitempty"` // 字段中要紧挨着写,omitempty 忽略空值
}
// 推荐使用msgpack
func f_1_4() {
var data = Person{"Jerry", 24}
// 序列化
b, err := msgpack.Marshal(data)
if err != nil {
panic(err)
}
fmt.Printf("%T %+[1]v \n", b)
// 反序列化
var p1 Person
err = msgpack.Unmarshal(b, &p1)
if err != nil {
panic(err)
}
fmt.Printf("%T %+[1]v \n", p1) // uint8 一个字节
// 序列化后得到的结果、数据类型、数据
}
Base64编码
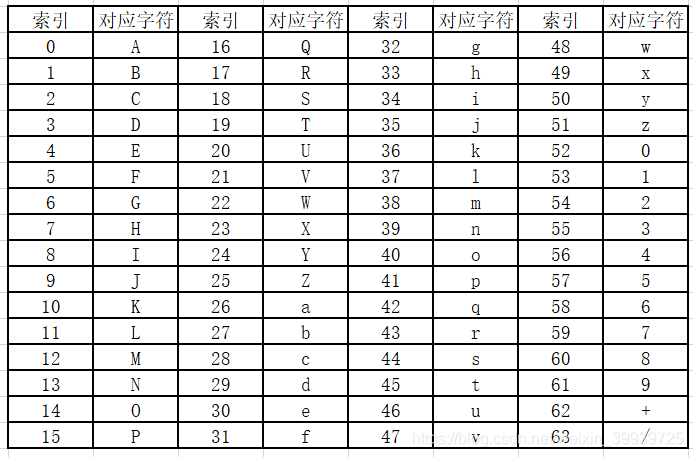
参考 https://en.wikipedia.org/wiki/Base64
简单来讲
- 编码过程就是对3个任意字节数据编程4个字节,每个字节的最高2位不用了,只用6位,而6位的变 化只有64种,如上图,利用上图查表对应就得出编码了。字节不够3会补齐
- 解码过程是对4个字节的base64编码的数据的每个字节去掉最高2位然后合并为3个字节
主要应用在JWT、网页图片传输等。
参考 base64 package - encoding/base64 - Go Packages
package main
import (
"encoding/base64"
"fmt"
)
func f_1_5() {
src := "abc" // 3bytes => 4bytes
s := base64.StdEncoding.EncodeToString([]byte(src))
fmt.Println(len(s), s)
fmt.Println("——————————————————")
b, err := base64.StdEncoding.DecodeString(s)
if err != nil {
panic(err)
}
fmt.Println(len(b), b)
t := string(b)
fmt.Println(len(t), t)
}