requests模块
requests 作为一个专门为「人类」编写的 HTTP 请求库,其易用性很强,因此在推出之后就迅速成为 Python 中首选的 HTTP 请求库。requests 库的最大特点是提供了简单易用的 API,让编程人员可以轻松地提高效率。由于 requests 不是 Python 的标准库,因此在使用之前需要进行安装:
pip install requests
通过 requests 可以完成各种类型的 HTTP 请求,包括 HTTP、HTTPS、HTTP1.0、HTTP1.1 及各种请求方法。requests 库支持的 HTTP 方法。
【1】requests支持的方法
requests模块支持的请求:
import requests
requests.get("http://httpbin.org/get")
requests.post("http://httpbin.org/post")
requests.put("http://httpbin.org/put")
requests.delete("http://httpbin.org/delete")
requests.head("http://httpbin.org/get")
requests.options("http://httpbin.org/get")
■ get——发送一个 GET 请求,用于请求页面信息。
■ options——发送一个 OPTIONS 请求,用于检查服务器端相关信息。
■ head——发送一个 HEAD 请求,类似于 GET 请求,但只请求页面的响应头信息。
■ post——发送一个 POST 请求,通过 body 向指定资源提交用户数据。
■ put——发送一个 PUT 请求,向指定资源上传最新内容。
■ patch——发送一个 PATCH 请求,同 PUT 类似,可以用于部分内容更新。
■ delete——发送一个 DELETE 请求,向指定资源发送一个删除请求。
可以看到,requests 使用与 HTTP 请求方法同名的 API 来提供相应的 HTTP 请求服务,从而降低了编程人员的学习和记忆成本。另外,这些 API 方法都调用同一个基础方法,因此在调用参数的使用上也基本保持一致。
import requests
res = requests.get("https://www.taobao.com/")
# print(res.text)
with open("taobao.html", "wb") as f:
f.write(res.content)
【2】requests的响应信息
1. 基本信息
print(respone.status_code)
print(respone.headers)
print(respone.text)
print(response.json)
2. 编码
print(respone.content)
print(response.encoding)
3. 下载图片、视频
# 下载图片
import requests
res = requests.get("https://img0.baidu.com/it/u=3330672963,1063627283&fm=253&fmt=auto&app=138&f=JPEG?w=500&h=281")
with open("美女.jpg", "wb") as f:
f.write(res.content)
# 下载视频
import requests
res = requests.get("https://video.pearvideo.com/mp4/adshort/20180613/cont-1365496-12251302_adpkg-ad_hd.mp4")
with open("梨视频.mp4", "wb") as f:
for item in res.iter_content():
f.write(item)
【3】requests的请求参数
1. 请求头参数
(1)UA反爬
访问百度首页的新闻信息
# 爬取百度首页
res = requests.get("https://www.baidu.com/")
res.encoding = "utf8"
with open("baidu.html", "wb") as f:
f.write(res.content)
结果是:
这里就涉及到了最简单的UA反爬,百度服务器通过UA请求头辨别是否为正常请求用户,所以为了攻破这个简单的反爬,只需要在requests请求中加入UA请求头即可。
res = requests.get("https://www.baidu.com/", headers={
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"
})
基于xpath解析新闻数据:
import requests
from lxml import etree
# 百度首页
res = requests.get("https://www.baidu.com/", headers={
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"
})
selector = etree.HTML(res.text)
items = selector.xpath('//ul[@class="s-hotsearch-content"]/li[contains(@class,"hotsearch-item")]')
print("items:", items)
for item in items:
href = item.xpath('./a/@href')[0]
title = item.xpath('.//span[@class="title-content-title"]/text()')[0]
print(title, href)
(2)Referer反爬
import requests
# https://movie.douban.com/explore
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',
'Referer': 'https://movie.douban.com/explore',
}
url = 'https://m.douban.com/rexxar/api/v2/movie/recommend?refresh=0&start=0&count=20&selected_categories=%7B%7D&uncollect=false&tags='
res = requests.get(url, headers=headers)
print(res.json())
items = res.json()['items']
for m in items:
print(m.get('title'))
2. 请求参数
import requests
# https://movie.douban.com/explore
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',
'Referer': 'https://movie.douban.com/explore',
}
url = 'https://m.douban.com/rexxar/api/v2/movie/recommend'
res = requests.get(url, headers=headers, params={
"tags": "欧美",
"sort": "S"
})
print(res.json())
items = res.json()['items']
for m in items:
print(m.get('title'))
3. 请求体数据
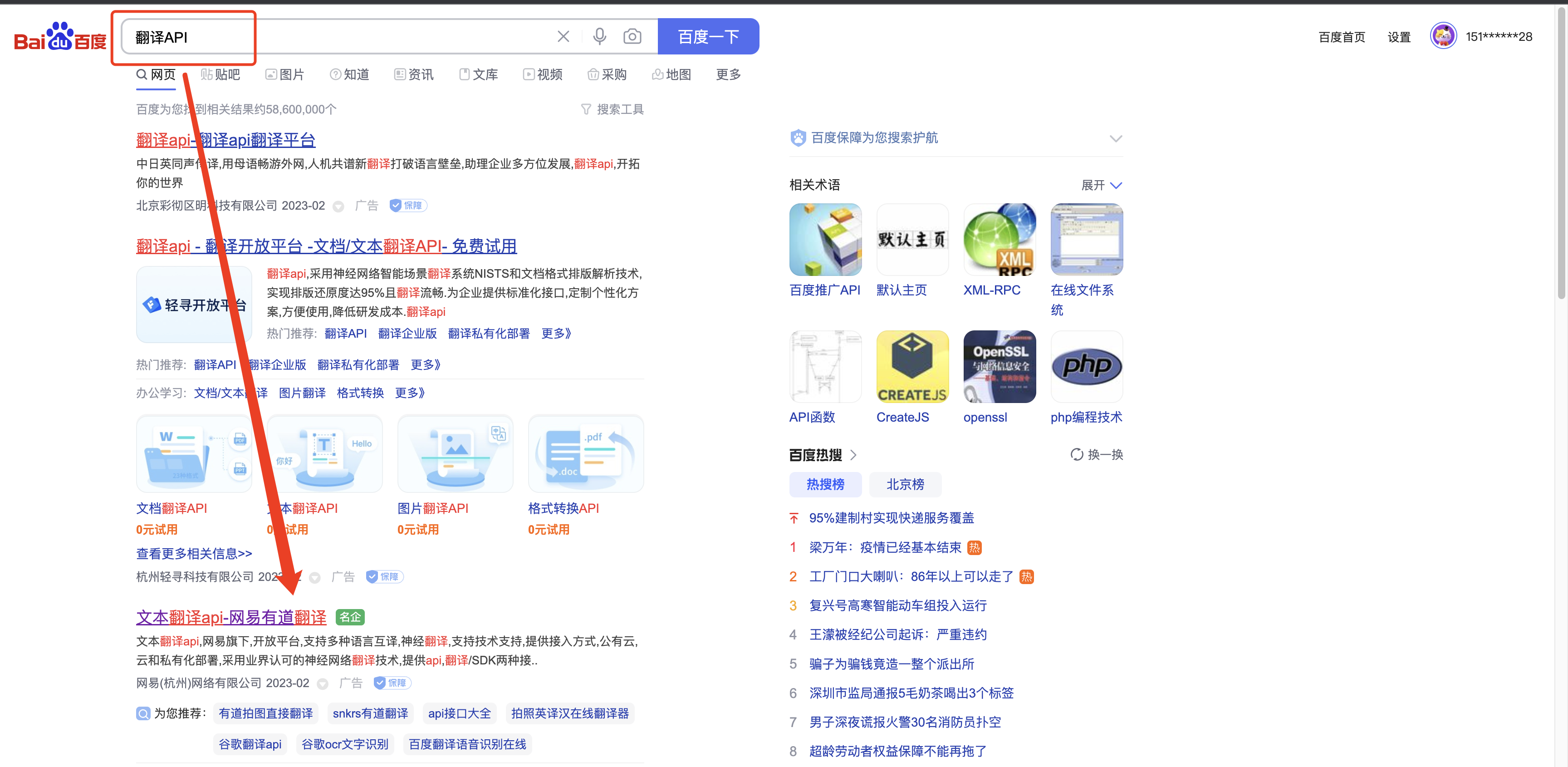
import requests
while 1:
kd = input("请输入翻译内容:")
res = requests.post("https://aidemo.youdao.com/trans", data={
"q": kd.strip()
})
# print(res.text)
print(res.json()["web"][0]["value"])
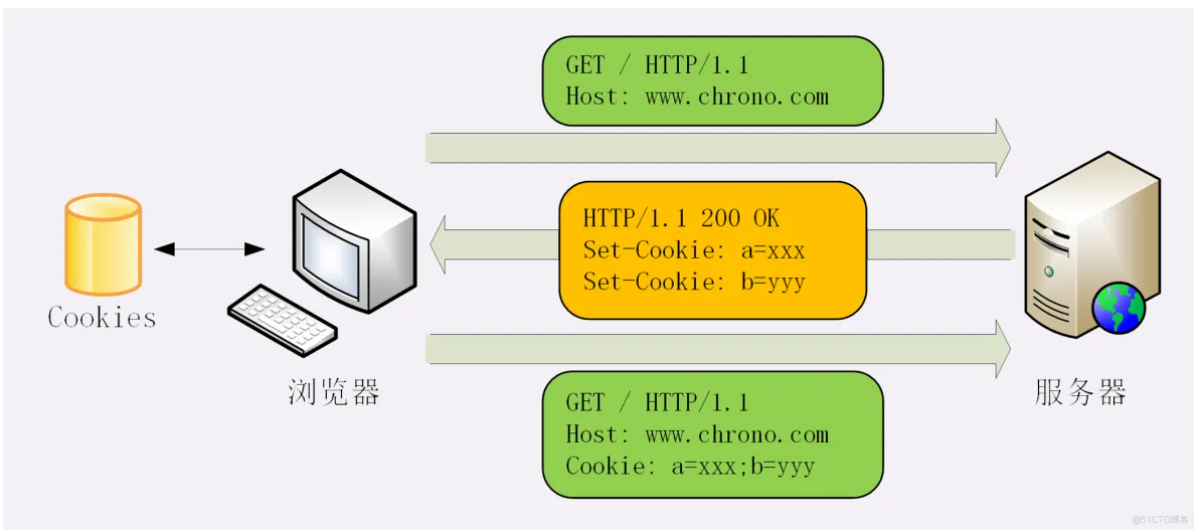
【4】Cookie与Session
(1)cookie的玩法
# server.py
from flask import Flask, request, make_response, render_template
import json
app = Flask(__name__, template_folder="temps")
COOKIE = "sadfnwejfnfcvxwerw213kbnkj2k3j23234jk2k"
@app.route("/login")
def login():
return render_template("login.html")
@app.route("/auth", methods=['POST'])
def auth():
user = request.form.get("user")
pwd = request.form.get("pwd")
if user == "yuan" and pwd == "123":
# 设置响应体
resp = make_response("登录成功")
resp.set_cookie("cookie", COOKIE)
return resp
else:
print("OK")
return "登录失败!"
@app.route("/")
def index():
return render_template("index.html")
@app.route("/books")
def books():
print(request.cookies.get("cookie"))
if request.cookies.get("cookie") == COOKIE:
data = ["西游记", "三国演义", "水浒传", "金瓶梅"]
return json.dumps(data, ensure_ascii=False)
else:
return "认证失败,请重新登录!"
if __name__ == '__main__':
app.run() # 默认端口号
# index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<script src="https://cdn.bootcdn.net/ajax/libs/jquery/3.5.1/jquery.js"></script>
</head>
<body>
<h1>四大名著</h1>
<p class="content"></p>
<script>
$.ajax({
url: "/books",
success: function (res) {
console.log(res)
$(".content").html(res)
}
})
</script>
</body>
</html>
(2)爬虫的cookie应用
# 请求cookie
requests.get(url="", headers={}, cookies={})
# 响应cookie
print(respone.cookies)
print(respone.cookies.get_dict())
print(respone.cookies.items())
session对象:该对象和requests模块用法几乎一致.如果在请求的过程中产生了cookie,如果该请求使用session发起的,则cookie会被自动存储到session中.
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',
}
# 获取从服务器端响应的cookie
url = 'https://xueqiu.com/'
res = requests.get(url, headers=headers)
cookies = dict(res.cookies)
url = 'https://stock.xueqiu.com/v5/stock/batch/quote.json?symbol=SH000001,SZ399001,SZ399006,SH000688,SH000016,SH000300,BJ899050,HKHSI,HKHSCEI,HKHSTECH,.DJI,.IXIC,.INX'
res = requests.get(url, headers=headers, cookies=cookies)
# print(res.json())
print(res.content.decode())
(2)session对象
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',
}
# 获取从服务器端响应的cookie
url = 'https://xueqiu.com/'
session = requests.session()
session.get(url, headers=headers)
url = 'https://stock.xueqiu.com/v5/stock/batch/quote.json?symbol=SH000001,SZ399001,SZ399006,SH000688,SH000016,SH000300,BJ899050,HKHSI,HKHSCEI,HKHSTECH,.DJI,.IXIC,.INX'
res = session.get(url, headers=headers)
print(res.json())
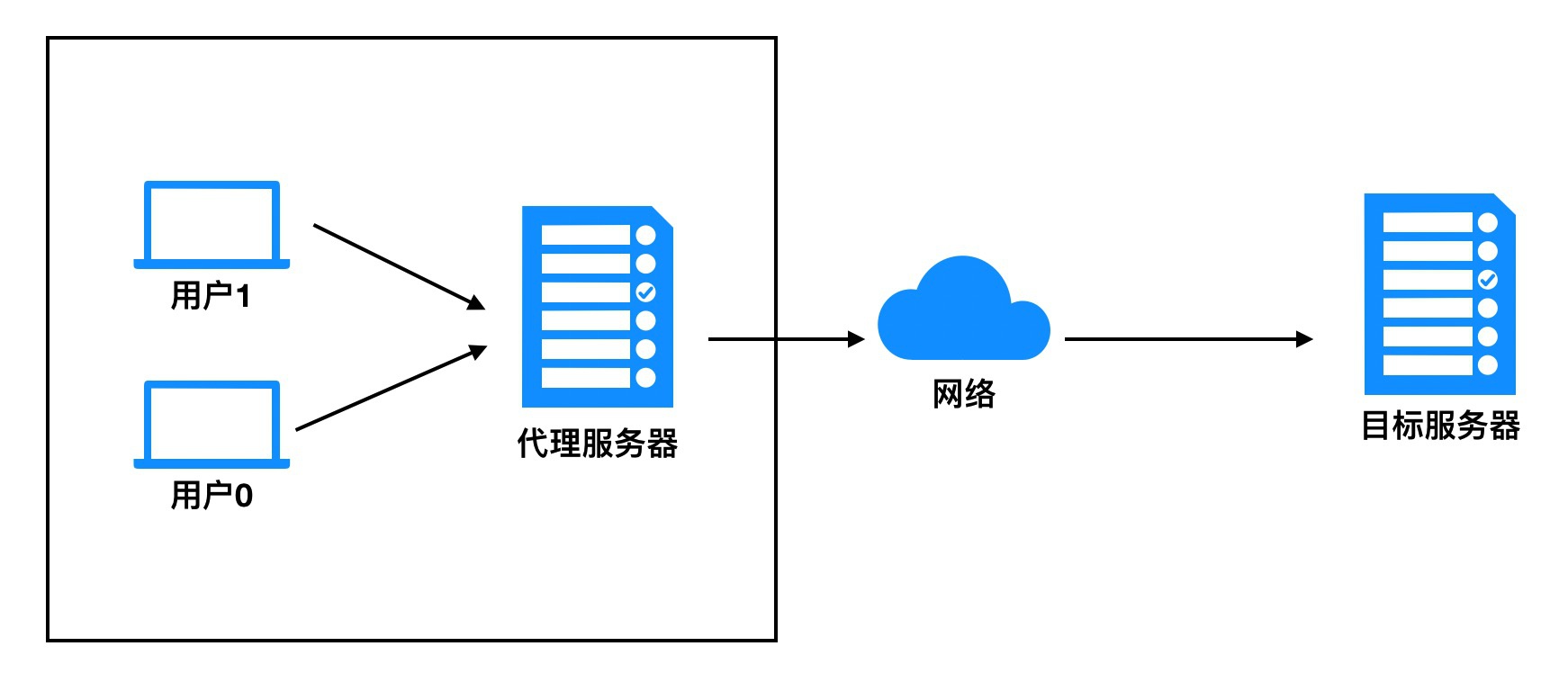
【5】代理IP
**代理IP:**反反爬使用代理ip是非常必要的一种反反爬的方式,但是即使使用了代理ip,对方服务器任然会有很多的方式来检测我们是否是一个爬虫,比如:一段时间内,检测IP访问的频率,访问太多频繁会屏蔽;检查Cookie,User-Agent,Referer等header参数,若没有则屏蔽;服务方购买所有代理提供商,加入到反爬虫数据库里,若检测是代理则屏蔽等。所以更好的方式在使用代理ip的时候使用随机的方式进行选择使用,不要每次都用一个代理ip
res = requests.get("http://httpbin.org/ip",
proxies={
"http": "101.132.25.152:50001"
}
)
print(res.text)
**代理ip池的更新:**购买的代理ip很多时候大部分(超过60%)可能都没办法使用,这个时候就需要通过程序去检测哪些可用,把不能用的删除掉。