传统CNN网络学习记录
CNN卷积神经网络算法原理
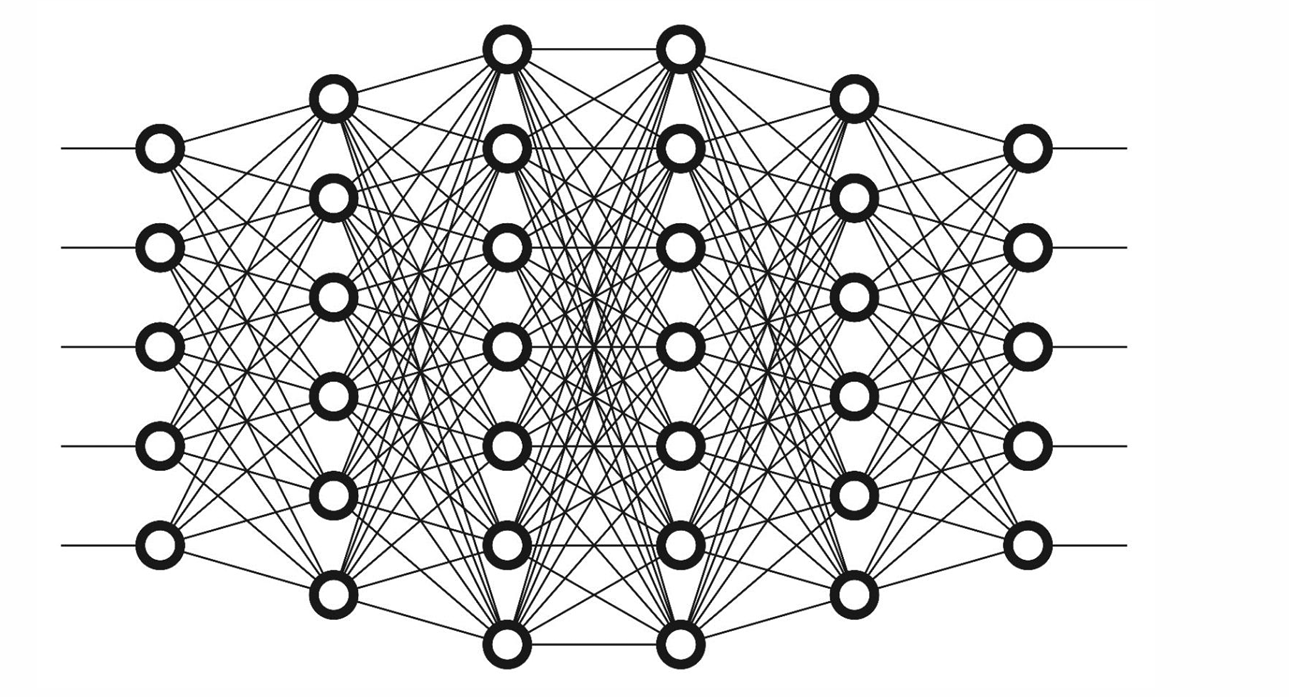
CNN结构
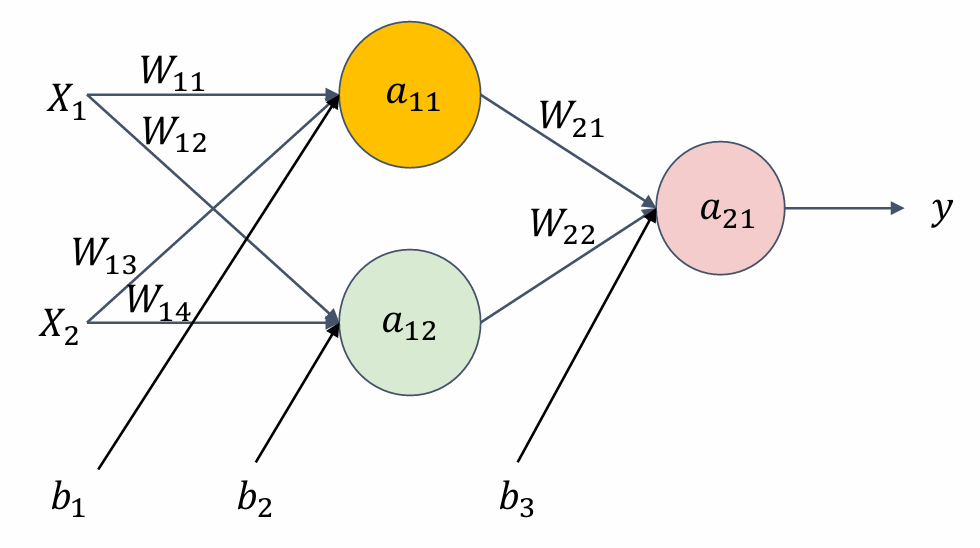
全连接神经网络的整体结构
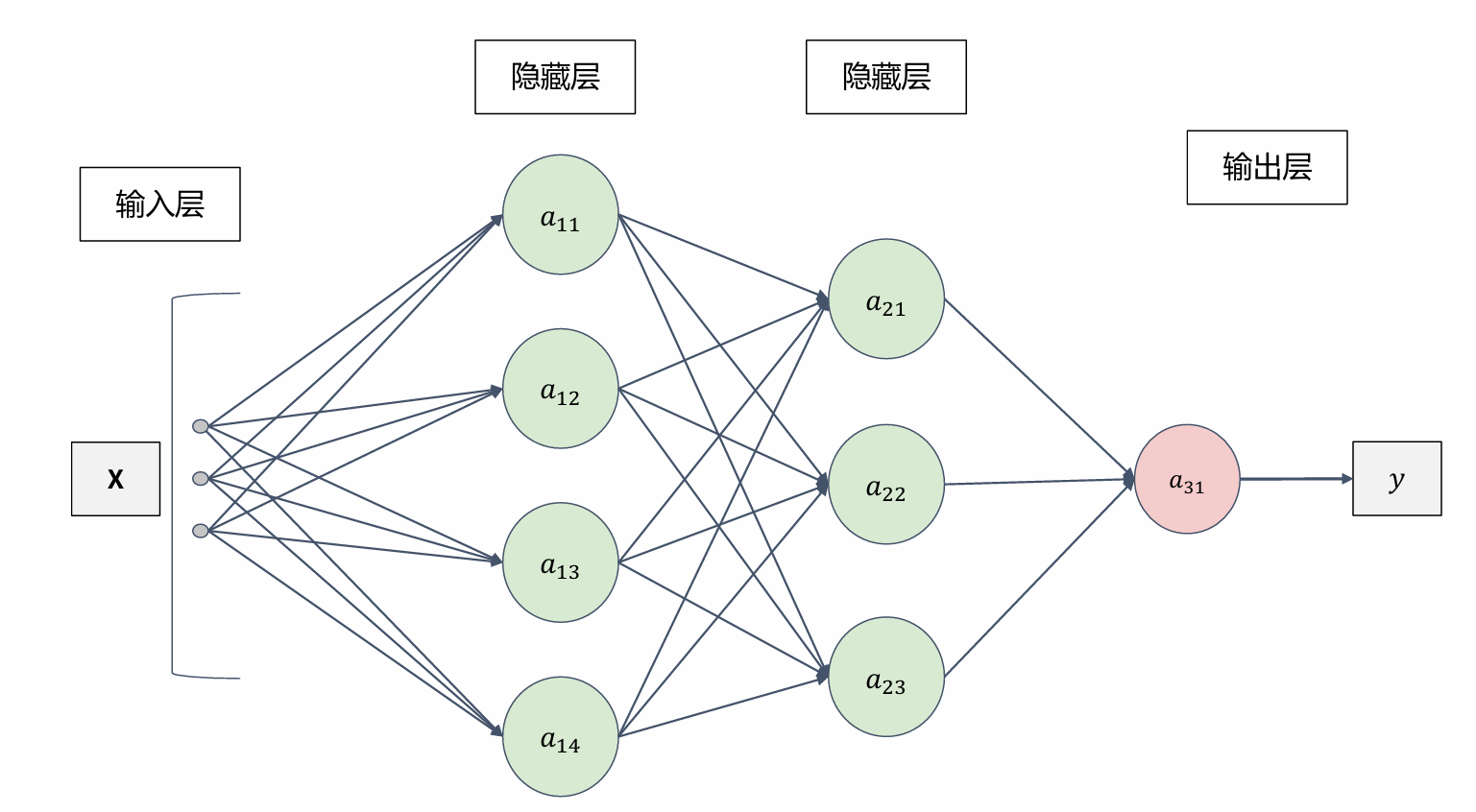
全连接神经网络的结构单元
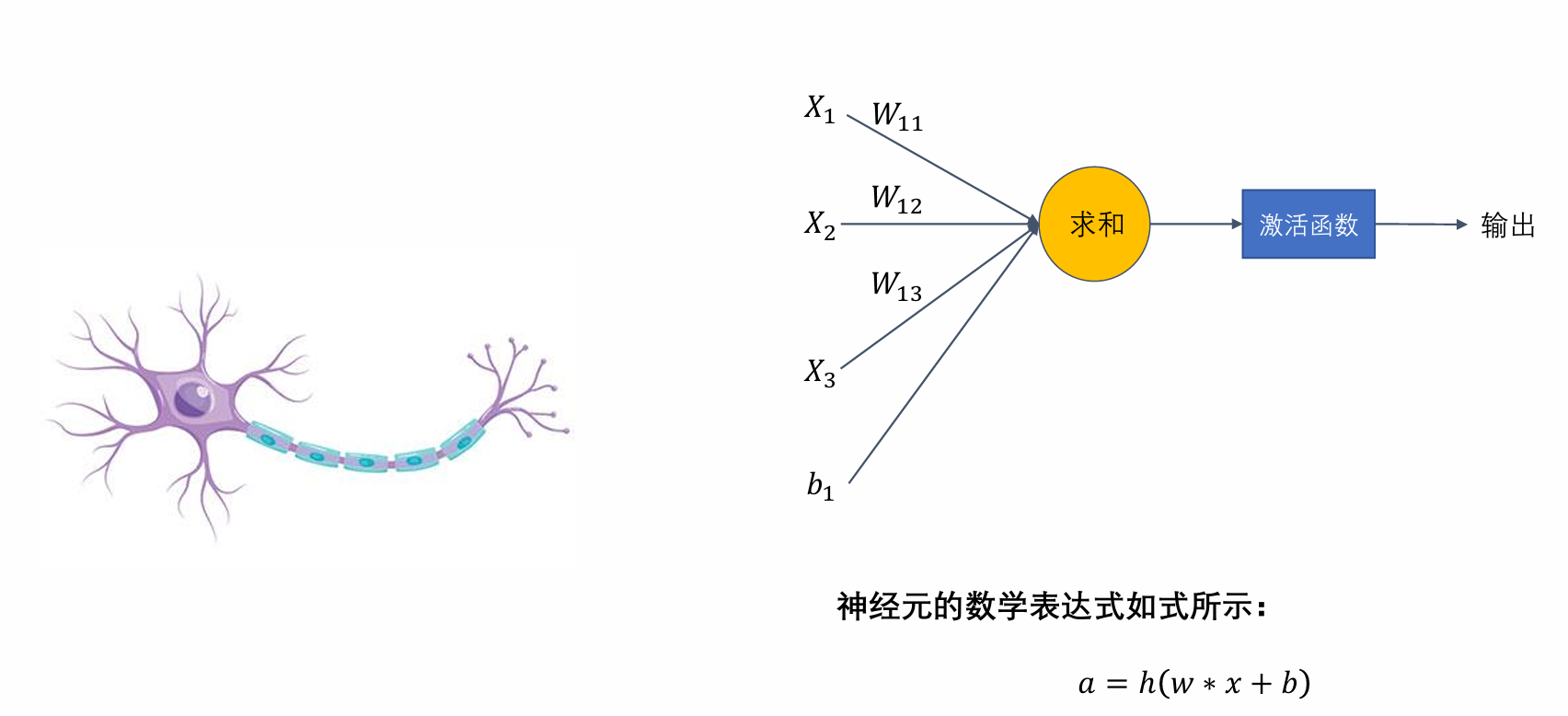
神经元的数学表达式为·
$a = h(w*x+b)$
为什么要加入激活函数?
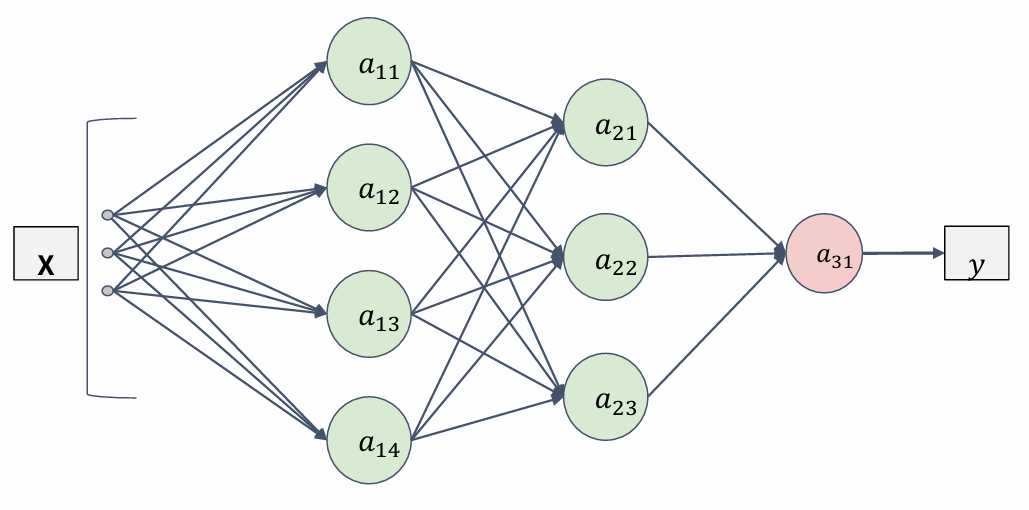
这里我们考虑把线性函数 $ℎ(𝑥)=𝑐𝑥$ 作为 激活函数,把 $𝑦(𝑥)=ℎ(ℎ(ℎ(𝑥)))$ 的运算 对应3层神经网络,这个运算会进行 $y(x)=ccc*x$的乘法运算,但是同 样的处理可以由$𝑦(𝑥)=𝑎𝑥$(注意,这里 $ a=𝑐∗∗3$)一次乘法运算(既没有隐藏 层的神经网络)来表示。
激活函数 【cv领域】
Sigmoid函数
Sigmoid函数的公式和导数如式表示:
$y=\frac{1}{1+e^-z}$ -------> $y’=y(1-y)$
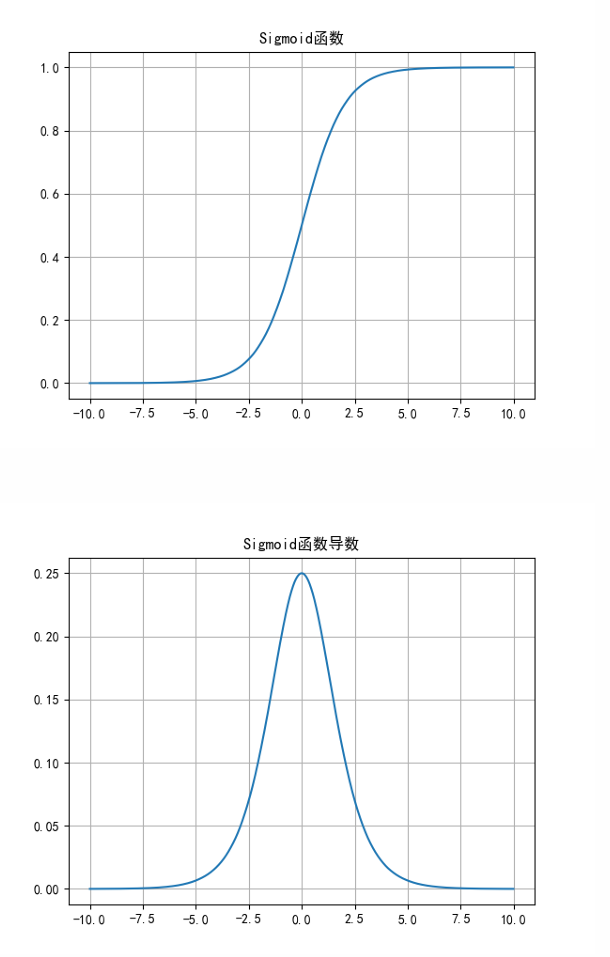
Sigmoid函数优点:
- 简单、非常适合分类任务
Sigmoid函数缺点
- 反向传播训练时有梯度消失的问题;
- 输出值区间为(0,1),关于0不对称;
- 梯度更新在不同方向走得太远,使得优化难度 增大,训练耗时
Tanh函数
Tanh函数和公式和导数如式所示:
$y = \frac{e^z - e-z}{ez + e^-z}$ -------> $y‘ = 1 -y^2$
Tanh函数优点:
-
解决了Sigmoid函数输出值非0对称的问题
-
训练比Sigmoid函数快,更容易收敛;
Tanh函数缺点:
- 反向传播训练时有梯度消失的问题;
- Tanh函数和Sigmoid函数非常相似。
ReLU函数
ReLU函数的公式和导数如式所示:
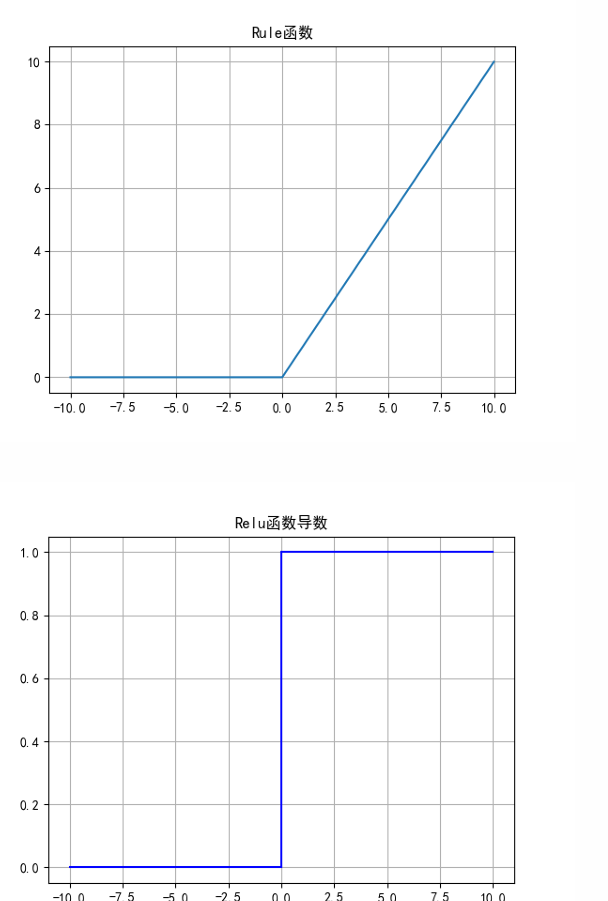
ReLU函数优点:
- 解决了梯度消失的问题;
- 计算更为简单,没有Sigmoid函数和Tanh函数 的指数运算;
ReLU函数缺点:
- 训练时可能出现神经元死亡;
Leaky ReLU函数
Leaky ReLU函数的公式和导数如式所示:
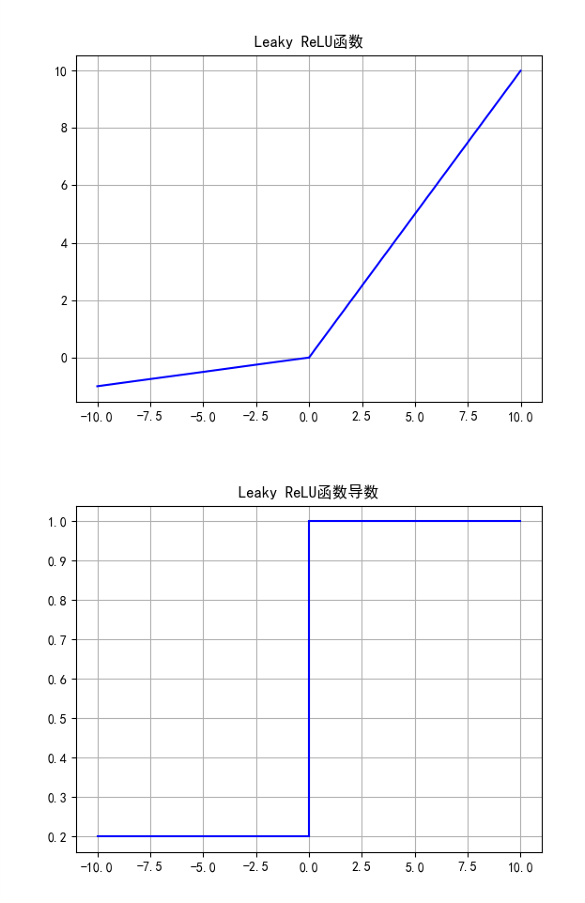
Leaky ReLU函数优点:
- 解决了ReLU的神经元死亡问题;
Leaky ReLU函数缺点:
- 无法为正负输入值提供一致的关系预测(不同区间函数不同)
前向传播算法

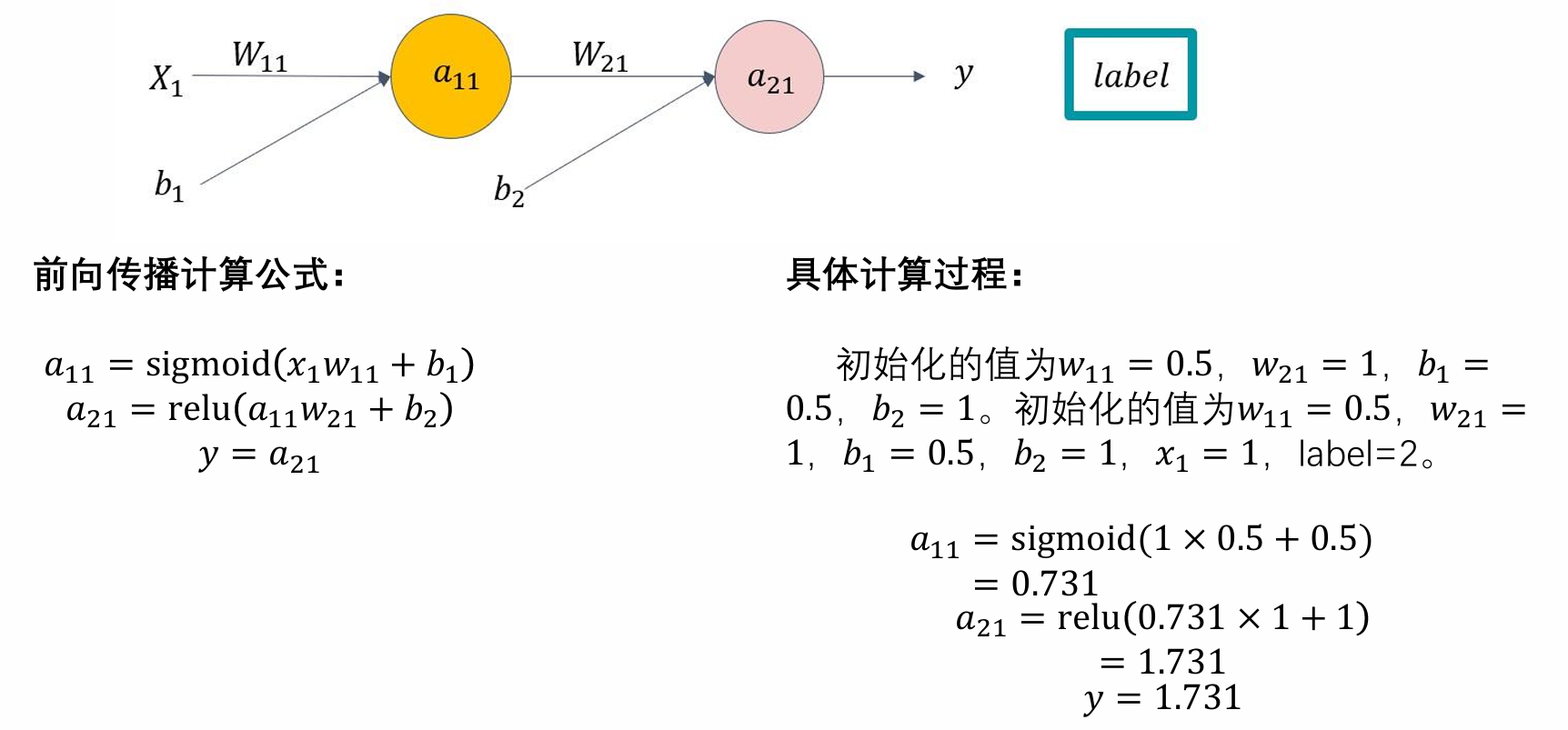
损失函数 【cv领域】
均方误差 (MSE)
平均绝对误差 (MAE)
交叉熵损失 (Cross Entropy Loss)
二元交叉熵 (Binary Cross Entropy)
LeNet&AleNet
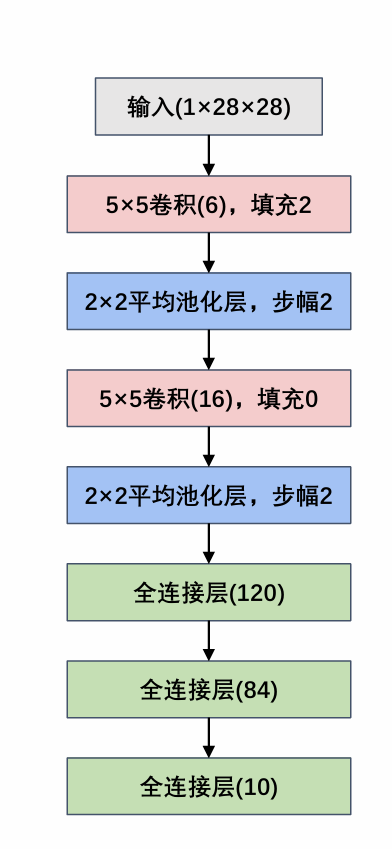
LeNet-5
结构图
import torch
from torch import nn
from torchsummary import summary
import torch.nn.functional as F
'''
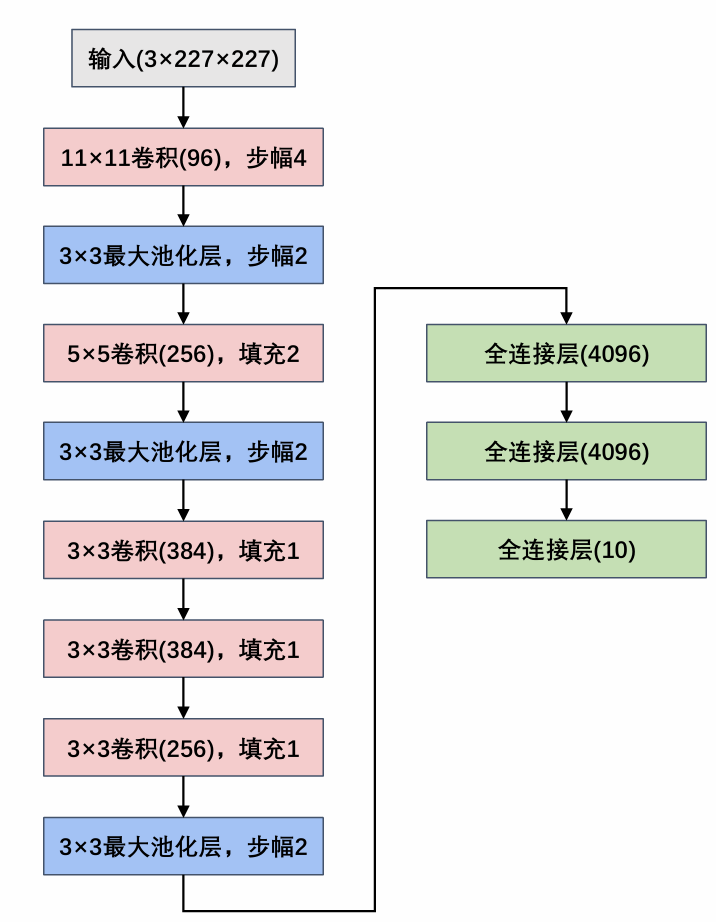
第1层输入层: Input为227×227×3
第2层卷积层: Input为227×227×3,卷积核为11×11×3× 96 ;stride=4,output为55×55×96
第3层最大池化层: Input为55×55×96,池化感受野为3×3,stride=2,output为27×27×96
第4层卷积层: Input为27×27×96,卷积核为5×5×96× 256 ;stride=1,padding=2 ,output为27×27×256
第5层最大池化层: Input为27×27×256,池化感受野为3 ×3,stride=2,output为13×13×256
第6层卷积层: Input为13×13×256,卷积核为3×3×256 × 384,stride=1,padding=1,output 为13×13×384
第7层卷积层: Input为13×13×384,卷积核为3×3×384 × 384,stride=1,padding=1,output 为13×13×384。
第8层卷积层: Input 13×13×384,卷积核为3×3×384 × 256,stride=1,padding=1,output 为13×13×256
第9层最大池化层: Input为13×13×256,池化感受野为3 ×3,stride=2,output 为6×6×256,Flatten操作,通过展平得到9216个数据后与之后的全连接层相连。
第10~12层全连接层:第10~12层神经元个数分别为4096,4096,1000。其中前两层在使用relu后还使用了Dropout对神经元随机失活,最后一层全连接层用softmax输出1000个分类(这里要说的是,softmax输出1000个分类原因是当时该网络设计是为了参加
ImageNet这个比赛,该比赛最后是对1000个物体进行分类)
'''
'''
in_channels
out_channels
kernel_size
stride 步幅
padding 填充
'''
class AlexNet(nn.Module):
def __init__(self):
# 继承
super(AlexNet,self).__init__()
self.relu = nn.ReLU() # 定义激活函数
self.c1 = nn.Conv2d(in_channels=1,out_channels=96,kernel_size=11,stride=4)
self.s2 = nn.MaxPool2d(kernel_size=3,stride=2)
self.c3 = nn.Conv2d(in_channels=96,out_channels=256,kernel_size=5,padding=2)
self.s4 = nn.MaxPool2d(kernel_size=3,stride=2)
self.c5 = nn.Conv2d(in_channels=256,out_channels=384,kernel_size=3,padding=1)
self.c6 = nn.Conv2d(in_channels=384, out_channels=384, kernel_size=3, padding=1)
self.c7 = nn.Conv2d(in_channels=384, out_channels=256, kernel_size=3, padding=1)
self.s8 = nn.MaxPool2d(kernel_size=3,stride=2)
self.flatten = nn.Flatten()
# 全连接层
self.f1 = nn.Linear(in_features=6*6*256,out_features=4096)
self.f2 = nn.Linear(in_features=4096,out_features=4096)
self.f3 = nn.Linear(in_features=4096,out_features=10) # 最后的输出为任务而定
def forward(self,x):
# 每次经过卷积都应该有个relu函数激活
x = self.relu(self.c1(x))
x = self.s2(x)
x = self.relu(self.c3(x))
x = self.s4(x)
x = self.relu(self.c5(x))
x = self.relu(self.c6(x))
x = self.relu(self.c7(x))
x = self.s8(x)
x = self.flatten(x)
x = self.relu(self.f1(x))
x = F.dropout(x,0.5) # 神经元随机失活,有0.5的神经元失活
x = self.relu(self.f2(x))
x = F.dropout(x,0.5)
x = self.f3(x)
return x
if __name__ == '__main__':
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = AlexNet()
model = model.to(device)
print(summary(model,(1,227,227)))
AleNet
结构图如下
Dropout 随机失活来提高网络的健壮性
随机失活,随机【临时】删除掉网络的一部分
import torch
from torch import nn
from torchsummary import summary
import torch.nn.functional as F
'''
第1层输入层: Input为227×227×3
第2层卷积层: Input为227×227×3,卷积核为11×11×3× 96 ;stride=4,output为55×55×96
第3层最大池化层: Input为55×55×96,池化感受野为3×3,stride=2,output为27×27×96
第4层卷积层: Input为27×27×96,卷积核为5×5×96× 256 ;stride=1,padding=2 ,output为27×27×256
第5层最大池化层: Input为27×27×256,池化感受野为3 ×3,stride=2,output为13×13×256
第6层卷积层: Input为13×13×256,卷积核为3×3×256 × 384,stride=1,padding=1,output 为13×13×384
第7层卷积层: Input为13×13×384,卷积核为3×3×384 × 384,stride=1,padding=1,output 为13×13×384。
第8层卷积层: Input 13×13×384,卷积核为3×3×384 × 256,stride=1,padding=1,output 为13×13×256
第9层最大池化层: Input为13×13×256,池化感受野为3 ×3,stride=2,output 为6×6×256,Flatten操作,通过展平得到9216个数据后与之后的全连接层相连。
第10~12层全连接层:第10~12层神经元个数分别为4096,4096,1000。其中前两层在使用relu后还使用了Dropout对神经元随机失活,最后一层全连接层用softmax输出1000个分类(这里要说的是,softmax输出1000个分类原因是当时该网络设计是为了参加
ImageNet这个比赛,该比赛最后是对1000个物体进行分类)
'''
'''
in_channels
out_channels
kernel_size
stride 步幅
padding 填充
'''
class AlexNet(nn.Module):
def __init__(self):
# 继承
super(AlexNet,self).__init__()
self.relu = nn.ReLU() # 定义激活函数
self.c1 = nn.Conv2d(in_channels=1,out_channels=96,kernel_size=11,stride=4)
self.s2 = nn.MaxPool2d(kernel_size=3,stride=2)
self.c3 = nn.Conv2d(in_channels=96,out_channels=256,kernel_size=5,padding=2)
self.s4 = nn.MaxPool2d(kernel_size=3,stride=2)
self.c5 = nn.Conv2d(in_channels=256,out_channels=384,kernel_size=3,padding=1)
self.c6 = nn.Conv2d(in_channels=384, out_channels=384, kernel_size=3, padding=1)
self.c7 = nn.Conv2d(in_channels=384, out_channels=256, kernel_size=3, padding=1)
self.s8 = nn.MaxPool2d(kernel_size=3,stride=2)
self.flatten = nn.Flatten()
# 全连接层
self.f1 = nn.Linear(in_features=6*6*256,out_features=4096)
self.f2 = nn.Linear(in_features=4096,out_features=4096)
self.f3 = nn.Linear(in_features=4096,out_features=10) # 最后的输出为任务而定
def forward(self,x):
# 每次经过卷积都应该有个relu函数激活
x = self.relu(self.c1(x))
x = self.s2(x)
x = self.relu(self.c3(x))
x = self.s4(x)
x = self.relu(self.c5(x))
x = self.relu(self.c6(x))
x = self.relu(self.c7(x))
x = self.s8(x)
x = self.flatten(x)
x = self.relu(self.f1(x))
x = F.dropout(x,0.5) # 神经元随机失活,有0.5的神经元失活
x = self.relu(self.f2(x))
x = F.dropout(x,0.5)
x = self.f3(x)
return x
if __name__ == '__main__':
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = AlexNet()
model = model.to(device)
print(summary(model,(1,227,227)))
VGG-16
力大砖飞 VGG
import torch
from torch import nn # 撰写网络
from torchsummary import summary # 验证
"使用nn.Sequential来模块化定义"
class VGG16(nn.Module):
def __init__(self):
super(VGG16,self).__init__()
# nn.Sequential 是序列的意思
self.block1 = nn.Sequential(
nn.Conv2d(in_channels=1,out_channels=64,kernel_size=3,padding=1,stride=1),
nn.ReLU(),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, padding=1, stride=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.block2 = nn.Sequential(
nn.Conv2d(in_channels=64,out_channels=128,kernel_size=3,padding=1,stride=1),
nn.ReLU(),
nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, padding=1, stride=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.block3 = nn.Sequential(
nn.Conv2d(in_channels=128,out_channels=256,kernel_size=3,padding=1,stride=1),
nn.ReLU(),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, padding=1, stride=1),
nn.ReLU(),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, padding=1, stride=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.block4 = nn.Sequential(
nn.Conv2d(in_channels=256,out_channels=512,kernel_size=3,padding=1,stride=1),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1, stride=1),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1, stride=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.block5 = nn.Sequential(
nn.Conv2d(in_channels=512,out_channels=512,kernel_size=3,padding=1,stride=1),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1, stride=1),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1, stride=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
)
# 全连接层
self.block6 = nn.Sequential(
nn.Flatten(), # 展开
nn.Linear(in_features=7*7*512,out_features=4096),
nn.ReLU(),
nn.Linear(in_features=4096,out_features=4096),
nn.ReLU(),
nn.Linear(in_features=4096,out_features=10),
)
# 参数初始化
for m in self.modules():
if isinstance(m,nn.Conv2d):
nn.init.kaiming_normal_(m.weight,nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias,0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight,0,0.01)
if m.bias is not None:
nn.init.constant_(m.bias,0)
def forward(self,x):
x = self.block1(x)
x = self.block2(x)
x = self.block3(x)
x = self.block4(x)
x = self.block5(x)
x = self.block6(x)
return x
if __name__ == '__main__':
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = VGG16().to(device)
print(summary(model,(1,224,224)))
GoogLeNet
GoogLeNet 提出
import torch
from torch import nn
from torchsummary import summary
'''Inception模块来实现模块化搭建'''
class Inception(nn.Module):
def __init__(self,in_channels,c1,c2,c3,c4): # c1,c2,c3,c4为输出通道数和输出通道数的数量
super(Inception,self).__init__()
self.rulu = nn.ReLU()
# 路线1,单1*1卷积层
self.p1 = nn.Conv2d(in_channels=in_channels,out_channels=c1,kernel_size=1)
# 路线2, 1*1卷积,3*3卷积
self.p2_1 = nn.Conv2d(in_channels=in_channels,out_channels=c2[0],kernel_size=1)
self.p2_2 = nn.Conv2d(in_channels=c2[0],out_channels=c2[1],kernel_size=3,padding=1)
# 路线3, 1*1卷积,5*5卷积
self.p3_1 = nn.Conv2d(in_channels=in_channels,out_channels=c3[0],kernel_size=1)
self.p3_2 = nn.Conv2d(in_channels=c3[0],out_channels=c3[1],kernel_size=5,padding=2)
# 路径4, 3*3最大池化,1*1卷积
self.p4_1 = nn.MaxPool2d(kernel_size=3,padding=1,stride=1) # 池化的步幅会和kernel_size相等
self.p4_2 = nn.Conv2d(in_channels=in_channels,out_channels=c4,kernel_size=1)
# 因为是并行的结构
def forward(self,x):
p1 = self.rulu(self.p1(x))
# 路径2
p2 = self.rulu(self.p2_2(self.rulu(self.p2_1(x))))
# 路线3
p3 = self.rulu(self.p3_2(self.rulu(self.p3_1(x))))
# 路线4
p4 = self.rulu(self.p4_2(self.p4_1(x)))
return torch.cat((p1,p2,p3,p4),dim=1) # 特征融合,dim=1指定为通道
class GoogLeNet(nn.Module):
def __init__(self,Inception):
super(GoogLeNet,self).__init__()
# 模块1
self.b1 = nn.Sequential(
nn.Conv2d(in_channels=1,out_channels=64,kernel_size=7,stride=2,padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,padding=1,stride=2)
)
# 模块2
self.b2 = nn.Sequential(
nn.Conv2d(in_channels=64,out_channels=64,kernel_size=1),
nn.ReLU(),
nn.Conv2d(in_channels=64, out_channels=192, kernel_size=3,padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,padding=1,stride=2)
)
'''以池化层为结尾作为区分'''
# 搭建Inception模块
self.b3 = nn.Sequential(
Inception(192,64, (96,128), (16,32), 32),
Inception(256,128, (128,192), (32,96), 64),
nn.MaxPool2d(kernel_size=3,padding=1,stride=2),
)
# 5个Inception
self.b4 = nn.Sequential(
Inception(480,192, (96,208), (16,48), 64),
Inception(512,160, (112,224), (24,64), 64),
Inception(512,128, (128, 256), (24, 64), 64),
Inception(512,112, (128, 288), (32, 64), 64),
Inception(528,256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3,padding=1,stride=2),
)
# 2个Inception
self.b5 = nn.Sequential(
Inception(832,256,(160,320),(32,128),128),
Inception(832,384,(192,384),(48,128),128),
nn.AdaptiveAvgPool2d((1,1)), # 全局平均池化
nn.Flatten(),
# 全连接层
nn.Linear(1024,10)
)
# 模型初始化
for m in self.modules():
if isinstance(m,nn.Conv2d):
nn.init.kaiming_normal_(m.weight,mode='fan_out',nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias,0)
elif isinstance(m,nn.Linear):
nn.init.normal_(m.weight,0,0.01) # 线性全连接层使用正态分布来初始化参数
if m.bias is not None:
nn.init.constant_(m.bias,0)
# 前向传播
def forward(self,x):
x = self.b1(x)
x = self.b2(x)
x = self.b3(x)
x = self.b4(x)
x = self.b5(x)
return x
'''模型测试'''
if __name__ == '__main__':
device = torch.device('cuda' if torch.cuda.is_available() else 'cup')
model = GoogLeNet(Inception).to(device)
print(summary(model,(1,224,224)))
ResNet
ResNet 残差网络,提出残差单元和凯明初始化
网络结构 ResNet-5
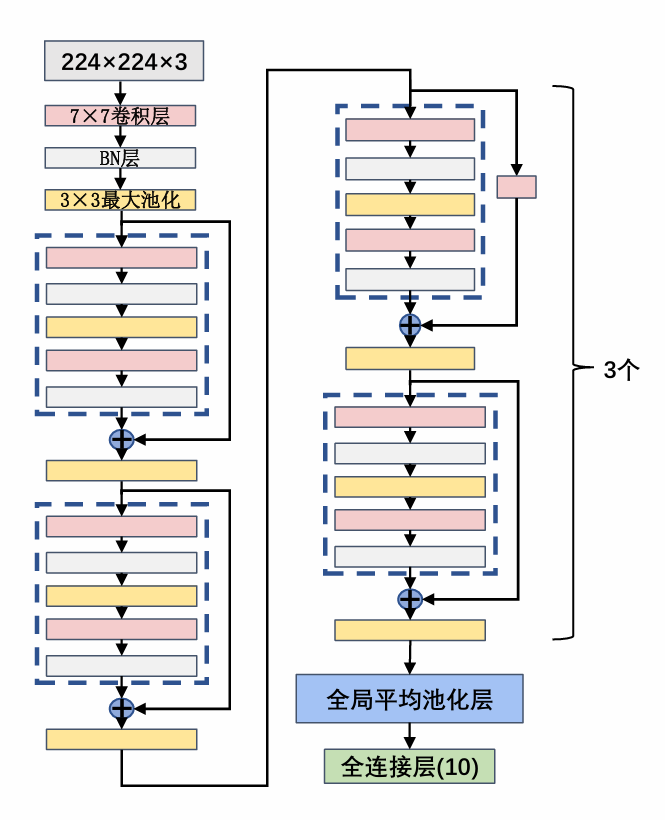
残差块:
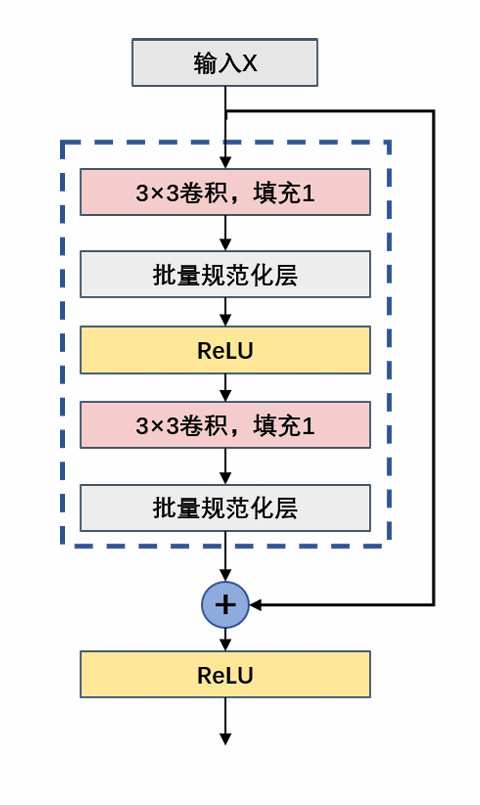
代码如下
import torch
from torch import nn
from torchsummary import summary
import torch.nn.functional as F
'''
第1层输入层: Input为227×227×3
第2层卷积层: Input为227×227×3,卷积核为11×11×3× 96 ;stride=4,output为55×55×96
第3层最大池化层: Input为55×55×96,池化感受野为3×3,stride=2,output为27×27×96
第4层卷积层: Input为27×27×96,卷积核为5×5×96× 256 ;stride=1,padding=2 ,output为27×27×256
第5层最大池化层: Input为27×27×256,池化感受野为3 ×3,stride=2,output为13×13×256
第6层卷积层: Input为13×13×256,卷积核为3×3×256 × 384,stride=1,padding=1,output 为13×13×384
第7层卷积层: Input为13×13×384,卷积核为3×3×384 × 384,stride=1,padding=1,output 为13×13×384。
第8层卷积层: Input 13×13×384,卷积核为3×3×384 × 256,stride=1,padding=1,output 为13×13×256
第9层最大池化层: Input为13×13×256,池化感受野为3 ×3,stride=2,output 为6×6×256,Flatten操作,通过展平得到9216个数据后与之后的全连接层相连。
第10~12层全连接层:第10~12层神经元个数分别为4096,4096,1000。其中前两层在使用relu后还使用了Dropout对神经元随机失活,最后一层全连接层用softmax输出1000个分类(这里要说的是,softmax输出1000个分类原因是当时该网络设计是为了参加
ImageNet这个比赛,该比赛最后是对1000个物体进行分类)
'''
'''
in_channels
out_channels
kernel_size
stride 步幅
padding 填充
'''
class AlexNet(nn.Module):
def __init__(self):
# 继承
super(AlexNet,self).__init__()
self.relu = nn.ReLU() # 定义激活函数
self.c1 = nn.Conv2d(in_channels=1,out_channels=96,kernel_size=11,stride=4)
self.s2 = nn.MaxPool2d(kernel_size=3,stride=2)
self.c3 = nn.Conv2d(in_channels=96,out_channels=256,kernel_size=5,padding=2)
self.s4 = nn.MaxPool2d(kernel_size=3,stride=2)
self.c5 = nn.Conv2d(in_channels=256,out_channels=384,kernel_size=3,padding=1)
self.c6 = nn.Conv2d(in_channels=384, out_channels=384, kernel_size=3, padding=1)
self.c7 = nn.Conv2d(in_channels=384, out_channels=256, kernel_size=3, padding=1)
self.s8 = nn.MaxPool2d(kernel_size=3,stride=2)
self.flatten = nn.Flatten()
# 全连接层
self.f1 = nn.Linear(in_features=6*6*256,out_features=4096)
self.f2 = nn.Linear(in_features=4096,out_features=4096)
self.f3 = nn.Linear(in_features=4096,out_features=10) # 最后的输出为任务而定
def forward(self,x):
# 每次经过卷积都应该有个relu函数激活
x = self.relu(self.c1(x))
x = self.s2(x)
x = self.relu(self.c3(x))
x = self.s4(x)
x = self.relu(self.c5(x))
x = self.relu(self.c6(x))
x = self.relu(self.c7(x))
x = self.s8(x)
x = self.flatten(x)
x = self.relu(self.f1(x))
x = F.dropout(x,0.5) # 神经元随机失活,有0.5的神经元失活
x = self.relu(self.f2(x))
x = F.dropout(x,0.5)
x = self.f3(x)
return x
if __name__ == '__main__':
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = AlexNet()
model = model.to(device)
print(summary(model,(1,227,227)))