关于字符编码哪些事
基础知识
数据在计算机中是使用 二进制 来存储的
**字符集(Charset):**是一个系统支持的所有抽象字符的集合。字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。
**字符编码(Character Encoding):**是一套法则,使用该法则能够对自然语言的字符的一个集合(如字母表或音节表),与其他东西的一个集合(如号码或电脉冲)进行配对。
什么是 编码 ?
f( 字符 ) = 二进制 -----> 这个过程就是编码 encode
f(二进制) = 字符 ----> 解码 decode
而这个 **f(x) **就是 编码规则
各个编码的关系
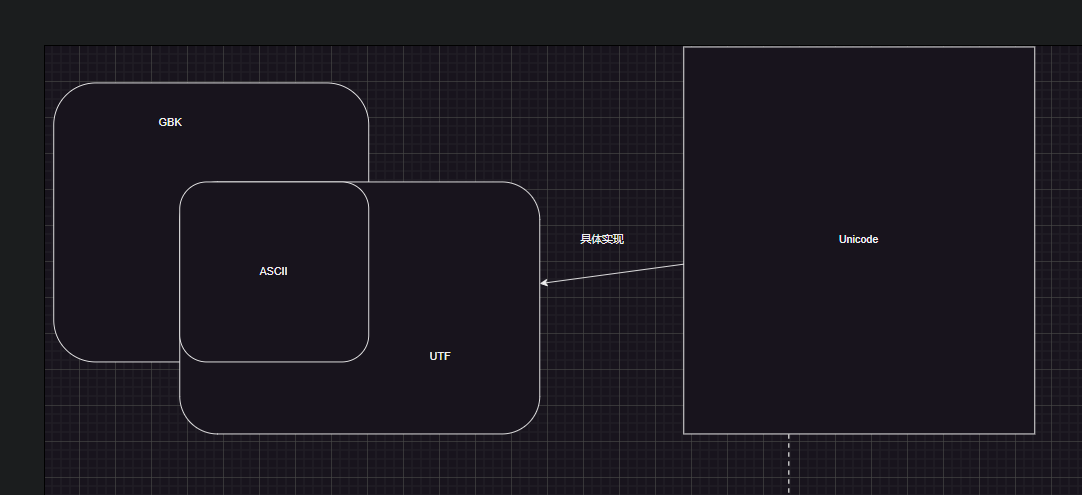
ASCII
上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为 ASCII 码,一直沿用至今。
采用8位,共 2^8 -1 个字符 -----> 256个
0000 0000 ----> 1111 1111

例如
SPACE (空格键) -------> 0010000
英文采用128个字符就够了,但是其他国家的语言,8位可不够,,必须采取其他的方式来编码
GBK
中国自己使用的兼容ASCII和中文的编码
GBK很早便实现了,所以他不是基于Unicode规则来编码的算法
但是他支持 很多国家的语言,like 数学符号、罗马希腊的 字母、日文的假名们都编进去了
Base64
Base64编码,是由64个字符组成编码集:26个大写字母AZ,26个小写字母az,10个数字0~9,符号“+”与符号“/”。Base64编码的基本思路是将原始数据的三个字节拆分转化为四个字节,然后根据Base64的对应表,得到对应的编码数据。
当原始数据凑不够三个字节时,编码结果中会使用额外的**符号“=”**来表示这种情况。
针对字节编码
编码原理
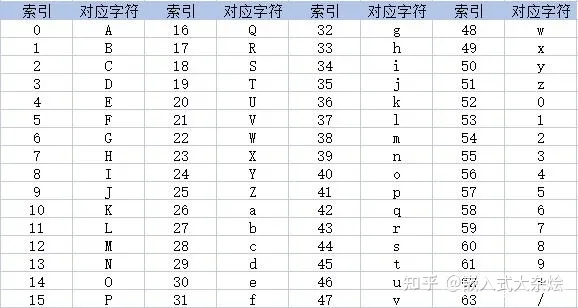
一个Base64字符实际上代表着6个二进制位(bit),4个Base64字符对应3字节字符串/二进制数据。
3个字符为一组的的base64编码方式如:
小于3个字符为一组的编码方式如:
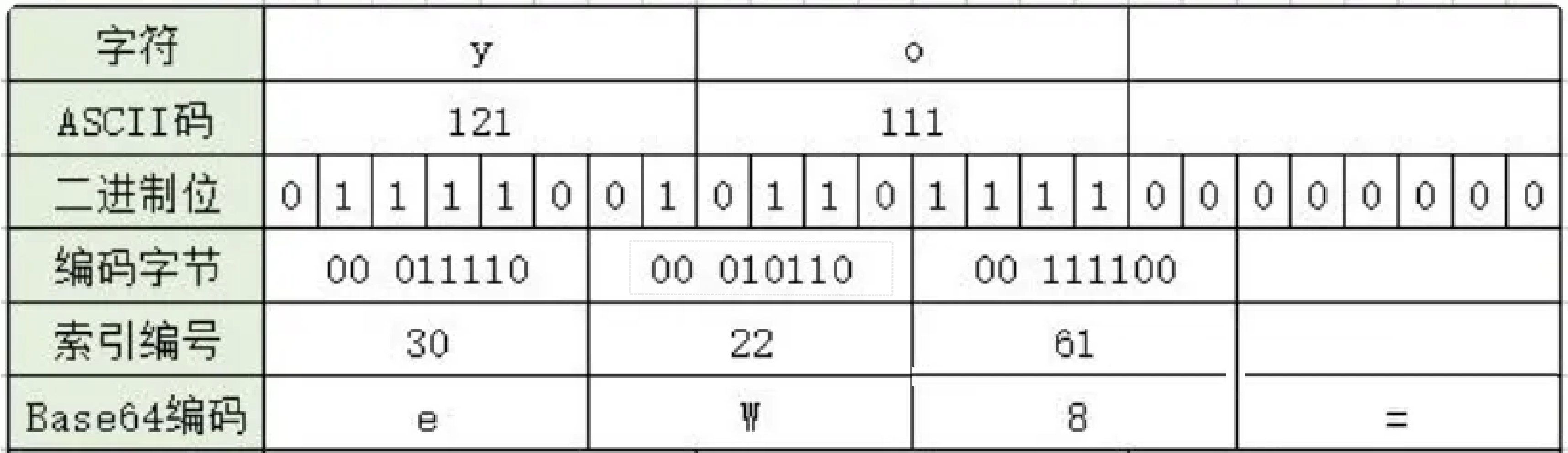
总结:base64过程
过程
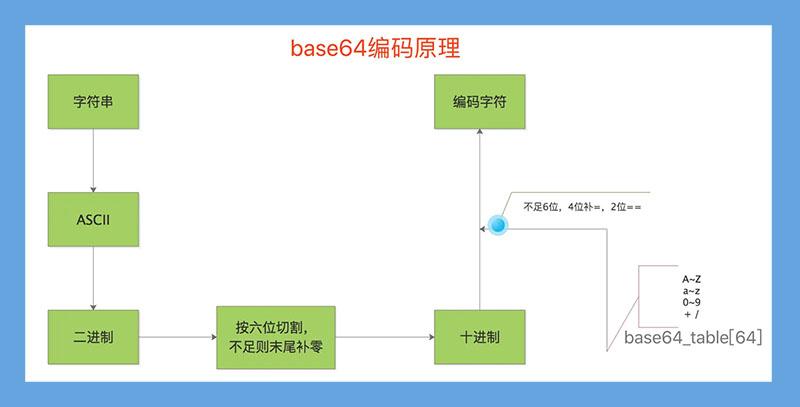
最后处理完的编码字符再转字节中不再有base64以外的任何字符。
意义
使用Base64编码后的数据 不会出现特殊的字符!
base64 编码的优点:
- 算法是编码,不是压缩,编码后只会增加字节数(一般是比之前的多1/3,比如之前是3, 编码后是4)
- 算法简单,基本不影响效率
- 算法可逆,解码很方便,不用于私密传输。
- 毕竟编码了,肉眼不能直接读出原始内容。
- 加密后的字符串只有【0-9a-zA-Z+/=】 ,不可打印字符(转译字符)也可以传输(关键!!!)
有些网络传输协议是为了传输ASCII文本设计的,当你使用其传输二进制流时(比如视频/图片),二进制流中的数据可能会被协议错误的识别为控制字符等等,因而出现错误。那这时就要将二进制流传输编码,因为有些8Bit字节码并没有对应的ASCII字符。
比如十进制ASCII码8对应的是后退符号(backspace), 如果被编码的数据中包含这个数值,那么编码出来的结果在很多编程语言里会导致前一个字符被删掉。又比如ASCII码0对应的是空字符,在一些编程语言里代表字符串结束,后续的数据就不会被处理了。
用Base64编码因为限定了用于编码的字符集,确保编码的结果可打印且无歧义。
不同的网络节点设备交互数据需要:设备A把base64编码后的数据封装在json字符串里,设备B先解析json拿到value,再进行base64解码拿到想要的数据。
早年制定的一些协议都是只支持文本设定的。随着不断发展需要支持非文本了,才搞了一个base64做兼容
虽然编码之后的数据与加密一样都具有不可见性,但编码与加密的概念并不一样。编码是公开的,任何人都可以解码;而加密则相反,你只希望自己或者特定的人才可以对内容进行解密。
Unicode
世界上存在着多种编码方式,同一个二进制数字可以被解释成不同的符号。因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。为什么电子邮件常常出现乱码?就是因为发信人和收信人使用的编码方式不一样。
Unicode 便是将世界所有的符号纳入其中。将每个符号都赋予一个独一无二的编码。
Unicode是一个巨大的集合
Unicode问题
需要注意的是,Unicode 只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
Unicode 不规定具体的存储方式,但提供了每个字符的标准编号。
例如:
U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字严
“严” 的Unicode码为 十六进制 4E25 即100111000100101
-
如何兼容ASCII?
- 直接使用,计算机怎么知道用的是Unicode还是3个ASCII
-
Unicode编码对存储来说太浪费了
- 对于使用英文的计算机来说,这也太浪费空间了。本来就1字节就能存储,现在要3/4个字节。文件大小直接大了3倍以上
UTF8
**互联网的普及,强烈要求出现一种统一的编码方式。**UTF-8 就是在互联网上使用最广的一种 Unicode 的实现方式。其他实现方式还包括 UTF-16(字符用两个字节或四个字节表示)和 UTF-32(字符用四个字节表示),不过在互联网上基本不用。重复一遍,这里的关系是,UTF-8 是 Unicode 的实现方式之一。
特点
- UTF8是 Unicode 的一种具体存储实现方式(即编码方案)。
- 可变长的编码,使用1~4个字节来表示一个符号,根据不同的符号而改变字节长度
编码规则
-
对于单字节的符号:字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的;
- 如:[ASCII下] “A” —> 0x41 ----> 0100 0001
- [UTF8]下 ”A“ -----> 0x41 -----> 0100 0001
- 如:[ASCII下] “A” —> 0x41 ----> 0100 0001
-
对于n字节的符号(n > 1):第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
系统的编码
unix和类unix编码采用的是 utf-8编码
windows为了兼容性问题(兼容老系统和老软件),不同的国家使用的编码不太相同。
参考文章
知乎: