funasr paraformer 介绍
funasr 框架介绍
paraformer 模型
paraformer 数据准备
数据格式要求
paraformer-16k模型 训练的音频文件最好大小一致,比较均匀,音频长度在一定范围,不然会炸炉子
我寻找到的数据:
- 16khz采样率
- 单通道
- 3-20s左右的.wav音频文件
训练的 jsonl 数据形如:
{"source": "wav/common_voice_en_42696072.wav", "target": "But then something even more extraordinary happened."}
{"source": "wav/common_voice_en_42696165.wav", "target": "The division was then commanded by Major General John Hawkesworth."}
{"source": "wav/common_voice_en_42696166.wav", "target": "Her husband was Li Shi, the last emperor of Cheng Han."}
{"source": "wav/common_voice_en_42696167.wav", "target": "London advances against Ludington, Michigan, champions of the Central League."}
{"source": "wav/common_voice_en_42696168.wav", "target": "But his books were never best-sellers."}
{"source": "wav/common_voice_en_42696169.wav", "target": "No new team would replace them."}
案例:
- 数据来源
选择的是 cv-corpus-22.0-delta-2025-06-20大约 2w6k 条的 mp3 数据
1. 源数据转换
目的: 将数据初步转化为符合训练条件的数据
由于训练要求的数据是16khz,单通道的 wav 格式数据
而 torchaudio 不支持 mp3 文件
所以需要借助 FFmpeg 来进行数据转换
- Linux
- Windows
- 去官网下载 zip 包,找个目录解压,将 bin 目录加入的 PATH
ffmpeg -version
可以运行,显示版本号就没问题
mp3 ——-> 16khz,单通道 wav
- python
使用 python 的多进程池来 并发处理 各个文件
import os
import subprocess
from concurrent.futures import ThreadPoolExecutor
# 多进程,使用 ffmpeg 将 mp3 转换为 wav 格式
def convert(mp3_path, wav_path):
subprocess.run([
"ffmpeg", "-y", "-i", mp3_path,
"-acodec", "pcm_s16le", "-ac", "1", "-ar", "16000", wav_path
])
mp3_dir = r""
wav_dir = r""
os.makedirs(wav_dir, exist_ok=True)
files = [f for f in os.listdir(mp3_dir) if f.lower().endswith(".mp3")]
with ThreadPoolExecutor(max_workers=8) as pool:
for f in files:
mp3_path = os.path.join(mp3_dir, f)
wav_path = os.path.join(wav_dir, os.path.splitext(f)[0] + ".wav")
pool.submit(convert, mp3_path, wav_path)
OR
- bash
mkdir -p ../wav
ls *.mp3 | xargs -P 8 -I{} ffmpeg -y -i "{}" -acodec pcm_s16le -ac 1 -ar 16000 "../wav/{}.wav"
转化时间可能有点久,需要一定的时间
2. tsv转为jsonl
import csv
import json
def tsv_to_jsonl(tsv_path, jsonl_path,data_path):
count = 0
with open(tsv_path, 'r', encoding='utf-8') as fin, open(jsonl_path, 'w', encoding='utf-8') as fout:
reader = csv.DictReader(fin, delimiter='\t')
for row in reader:
audio_path = row.get("path", "").strip()
text = row.get("sentence", "").strip()
if not audio_path or not text:
print(f"跳过缺失字段的行: {row}")
continue
#
audio_path = audio_path.replace(".mp3",".wav")
json_obj = {
"source": f"{data_path}"+audio_path,
"target": text
}
fout.write(json.dumps(json_obj, ensure_ascii=False) + '\n')
count += 1
print(f"转换完成,共写入 {count} 条记录到 {jsonl_path}")
if __name__ == "__main__":
tsv_file = "../exp/tsv/other.tsv" # 替换为你的文件名
jsonl_file = "data.jsonl" # 输出文件名
data_path = "/" # data的绝对路径
tsv_to_jsonl(tsv_file, jsonl_file,data_path)
3. 数据过滤
数据集中有一些比较大的mp3文件,要将其过滤掉,太大的文件在训练的时候会 炸炉子(cuda out of memory)
目的: 删除过大的wav文件,我从大小的角度剔除文件,可以调整 size
import os
def list_large_wavs(folder, size_mb=1):
wav_files = []
for root, _, files in os.walk(folder):
for f in files:
if f.lower().endswith('.wav'):
path = os.path.join(root, f)
if os.path.getsize(path) > size_mb * 1024 *1024:
wav_files.append(f)
return wav_files
if __name__ == "__main__":
folder = input("请输入要扫描的文件夹路径: ").strip()
large_wavs = list_large_wavs(folder, size_mb=1)
with open("delete.txt", "w") as f:
for wav in large_wavs:
f.write(wav + "\n")
将需要剔除的数据过滤出来,在jsonl中过滤掉或者删除掉
- 剔除脚本
import json
import os
# 配置文件路径
jsonl_path = "./data.jsonl" # 原始jsonl文件
delete_txt = "delete.txt" # 包含要删除的文件名
output_path = "filtered.jsonl" # 输出的新jsonl文件
# 读取要删除的文件名集合
with open(delete_txt, "r", encoding="utf-8") as f:
delete_set = set(line.strip() for line in f if line.strip())
with open(jsonl_path, "r", encoding="utf-8") as fin, \
open(output_path, "w", encoding="utf-8") as fout:
for line in fin:
obj = json.loads(line)
wav_name = os.path.basename(obj.get("source", ""))
if wav_name not in delete_set:
fout.write(line)
print(f"过滤完成,结果已保存到 {output_path}")
4. 划分train/val
import json
import random
def split_jsonl(input_path, train_path, val_path, val_ratio=0.1, seed=42):
# 读取所有数据
with open(input_path, 'r', encoding='utf-8') as f:
data = [json.loads(line) for line in f if line.strip()]
# 打乱数据顺序
random.seed(seed)
random.shuffle(data)
# 按比例划分
val_size = int(len(data) * val_ratio)
val_data = data[:val_size]
train_data = data[val_size:]
# 写入train.jsonl
with open(train_path, 'w', encoding='utf-8') as f_train:
for item in train_data:
f_train.write(json.dumps(item, ensure_ascii=False) + '\n')
# 写入val.jsonl
with open(val_path, 'w', encoding='utf-8') as f_val:
for item in val_data:
f_val.write(json.dumps(item, ensure_ascii=False) + '\n')
print(f"总样本数: {len(data)}")
print(f"训练集: {len(train_data)} 条 -> {train_path}")
print(f"验证集: {len(val_data)} 条 -> {val_path}")
if __name__ == "__main__":
split_jsonl(
input_path="./filtered.jsonl",
train_path="../datas/en/train.jsonl",
val_path="../datas/en/val.jsonl",
val_ratio=0.1, # 可修改为0.2或其他值
seed=42 # 设置种子以确保结果可复现
)
Azure 虚拟机
Azure 虚拟机价格查询
Azure 的各种价格查询 Azure Pricing Overview | Microsoft Azure
去官网查看价格对比
我租用的虚拟机为 Standard NC24ads A100 v4 (24 vcpu,220 GiB 内存)
价格为:

选择带 nv gpu 的虚拟机
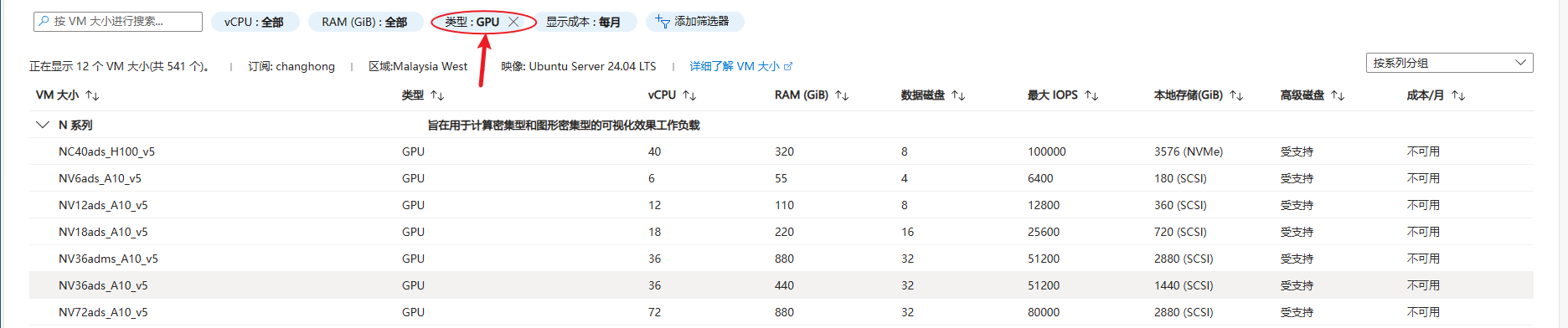
类型选择GPU,直接筛选出来
Tips:
- azure虚拟机部署的区域不同,vm的可用性可能不一样,比如有些地方的同型号虚拟机是没有配额的
- 其余选择默认的
- 磁盘容量可以适当扩大
安装 nv 驱动
在过去要先卸载原有驱动再安装,但是现在是2025,最新的 Ubuntu 24.04 LTS Server 已经可以一键安装了,有手就行!!
- 参考文档 :
适用于 Linux 的 Azure N 系列 GPU 驱动程序安装 - Azure Virtual Machines | Microsoft Learn
- 先查看自己电脑上是否有显卡:
lspci | grep -i NVIDIA
一般情况都有,没有显卡建议重新创建一下虚拟机了
Ubuntu 打包了 NVIDIA 的专有驱动程序,可以简单的一键安装
- 安装
ubuntu-drivers实用工具:
sudo apt update && sudo apt install -y ubuntu-drivers-common
- 安装最新的 NV 驱动:
sudo ubuntu-drivers install
- 安装 GPU 驱动程序后重新启动 VM:
sudo reboot
- 验证是否已正确识别 GPU(重启后):
nvidia-smi
cudatoolkit 是否需要安装?
在过去 nv 驱动安装起来很麻烦,cudatoolkit 安装起来更是烦人【现在一键傻瓜式安装】
现在的 pytorch 支持携带对应的cudatookit环境(携带cuda runtime),可以不用预先安装cudatookit,只要cuda version不是过新就可以。
cuda version 是可以向前兼容,12.8 的cuda 支持 使用 12.6的cudatookit,不是重度开发可以不用管!
这种情况就需要下载 CUDA Toolkit
- 你要自己编写、编译 CUDA C/C++ 代码(比如自定义 CUDA 算子、扩展 PyTorch)。
- 需要用 nvcc 编译器手动编译 CUDA 代码。
- 开发底层 GPU 加速库或工具。
pytroch携带的 cuda 运行时(cuda runtime)足够了
- 训练,部署
python环境依赖准备
pytroch
去官网查找:
选择一下对应的即可
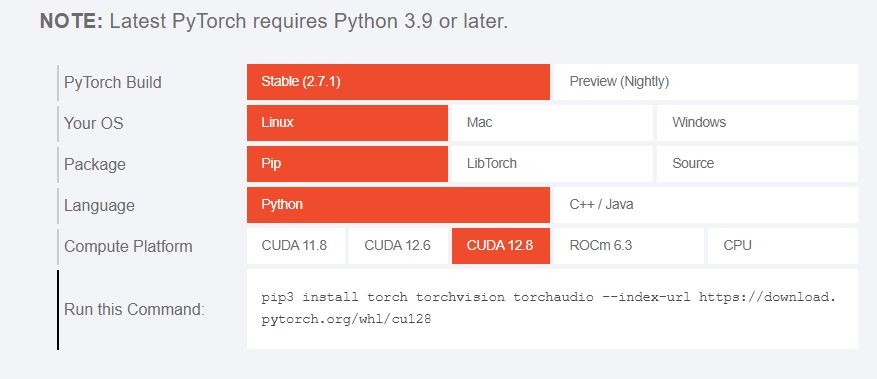
- 推荐uv下载
uv pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
funasr 相关
下载 funasr
uv pip install -U funasr
模型源下载
uv pip install -U modelscope huggingface_hub
测试环境是否ok?
- 测试cuda是否ok?
import torch
if torch.cuda.is_available():
print("CUDA is available.")
print(f"Device count: {torch.cuda.device_count()}")
print(f"Current device: {torch.cuda.current_device()}")
print(f"Device name: {torch.cuda.get_device_name(torch.cuda.current_device())}")
else:
print("CUDA is not available.")
运行显示 cuda is aviable 即证明 pytorch cuda runtime 安装成功
- 测试funasr是否ok?
"""
这个脚本也能执行
funasr ++model=paraformer-zh ++vad_model="fsmn-vad" ++punc_model="ct-punc" ++input=vad_example.wav
"""
from funasr import AutoModel
model = AutoModel(
model="paraformer-zh",
vad_model="fsmn-vad",
punc_model="ct-punc"
)
# 准备一个 1.wav 文件测试一下
res = model.generate(input=f"exp/1.wav")
print(res)
初次会下载 paraformer-zh 模型,然后加载推理,最终效果为:
运行成功!
开始训练
run
训练的目录结构:
— datas
— train_ds.py
— finetune.sh
- 拷贝官方的 train_ds.py
#!/usr/bin/env python3
# -*- encoding: utf-8 -*-
import os
import sys
import torch
import torch.nn as nn
import hydra
import logging
import time
import argparse
from io import BytesIO
from contextlib import nullcontext
import torch.distributed as dist
from omegaconf import DictConfig, OmegaConf
from torch.cuda.amp import autocast, GradScaler
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
from torch.distributed.algorithms.join import Join
from torch.distributed.fsdp.sharded_grad_scaler import ShardedGradScaler
from funasr.train_utils.average_nbest_models import average_checkpoints
from funasr.register import tables
from funasr.optimizers import optim_classes
from funasr.train_utils.trainer_ds import Trainer
from funasr.schedulers import scheduler_classes
from funasr.train_utils.initialize import initialize
from funasr.download.download_model_from_hub import download_model
from funasr.models.lora.utils import mark_only_lora_as_trainable
from funasr.train_utils.set_all_random_seed import set_all_random_seed
from funasr.train_utils.load_pretrained_model import load_pretrained_model
from funasr.utils.misc import prepare_model_dir
from funasr.train_utils.model_summary import model_summary
from funasr import AutoModel
try:
import deepspeed
except:
deepspeed = None
@hydra.main(config_name=None, version_base=None)
def main_hydra(kwargs: DictConfig):
if kwargs.get("debug", False):
import pdb
pdb.set_trace()
assert "model" in kwargs
if "model_conf" not in kwargs:
logging.info("download models from model hub: {}".format(kwargs.get("hub", "ms")))
kwargs = download_model(is_training=kwargs.get("is_training", True), **kwargs)
main(**kwargs)
def main(**kwargs):
# set random seed
set_all_random_seed(kwargs.get("seed", 0))
torch.backends.cudnn.enabled = kwargs.get("cudnn_enabled", torch.backends.cudnn.enabled)
torch.backends.cudnn.benchmark = kwargs.get("cudnn_benchmark", torch.backends.cudnn.benchmark)
torch.backends.cudnn.deterministic = kwargs.get("cudnn_deterministic", True)
# open tf32
torch.backends.cuda.matmul.allow_tf32 = kwargs.get("enable_tf32", True)
rank = int(os.environ.get("RANK", 0))
local_rank = int(os.environ.get("LOCAL_RANK", 0))
world_size = int(os.environ.get("WORLD_SIZE", 1))
if local_rank == 0:
tables.print()
use_ddp = world_size > 1
use_fsdp = kwargs.get("use_fsdp", False)
use_deepspeed = kwargs.get("use_deepspeed", False)
if use_deepspeed:
logging.info(f"use_deepspeed: {use_deepspeed}")
deepspeed.init_distributed(dist_backend=kwargs.get("backend", "nccl"))
elif use_ddp or use_fsdp:
logging.info(f"use_ddp: {use_ddp}, use_fsdp: {use_fsdp}")
dist.init_process_group(
backend=kwargs.get("backend", "nccl"),
init_method="env://",
)
torch.cuda.set_device(local_rank)
# rank = dist.get_rank()
logging.info("Build model, frontend, tokenizer")
device = kwargs.get("device", "cuda")
kwargs["device"] = "cpu"
model = AutoModel(**kwargs)
# save config.yaml
if rank == 0:
prepare_model_dir(**kwargs)
# parse kwargs
kwargs = model.kwargs
kwargs["device"] = device
tokenizer = kwargs["tokenizer"]
frontend = kwargs["frontend"]
model = model.model
del kwargs["model"]
# freeze_param
freeze_param = kwargs.get("freeze_param", None)
if freeze_param is not None:
if "," in freeze_param:
freeze_param = eval(freeze_param)
if not isinstance(freeze_param, (list, tuple)):
freeze_param = (freeze_param,)
logging.info("freeze_param is not None: %s", freeze_param)
for t in freeze_param:
for k, p in model.named_parameters():
if k.startswith(t + ".") or k == t:
logging.info(f"Setting {k}.requires_grad = False")
p.requires_grad = False
if local_rank == 0:
logging.info(f"{model_summary(model)}")
trainer = Trainer(
rank=rank,
local_rank=local_rank,
world_size=world_size,
use_ddp=use_ddp,
use_fsdp=use_fsdp,
device=kwargs["device"],
excludes=kwargs.get("excludes", None),
output_dir=kwargs.get("output_dir", "./exp"),
**kwargs.get("train_conf"),
)
model = trainer.warp_model(model, **kwargs)
kwargs["device"] = int(os.environ.get("LOCAL_RANK", 0))
trainer.device = int(os.environ.get("LOCAL_RANK", 0))
model, optim, scheduler = trainer.warp_optim_scheduler(model, **kwargs)
# dataset
logging.info("Build dataloader")
dataloader_class = tables.dataloader_classes.get(
kwargs["dataset_conf"].get("dataloader", "DataloaderMapStyle")
)
dataloader = dataloader_class(**kwargs)
# dataloader_tr, dataloader_val = dataloader_class(**kwargs)
scaler = GradScaler(enabled=True) if trainer.use_fp16 or trainer.use_bf16 else None
scaler = ShardedGradScaler(enabled=trainer.use_fp16) if trainer.use_fsdp else scaler
trainer.resume_checkpoint(
model=model,
optim=optim,
scheduler=scheduler,
scaler=scaler,
)
dataloader_tr, dataloader_val = None, None
for epoch in range(trainer.start_epoch, trainer.max_epoch):
time1 = time.perf_counter()
for data_split_i in range(trainer.start_data_split_i, dataloader.data_split_num):
time_slice_i = time.perf_counter()
dataloader_tr, dataloader_val = dataloader.build_iter(
epoch, data_split_i=data_split_i, start_step=trainer.start_step
)
trainer.train_epoch(
model=model,
optim=optim,
scheduler=scheduler,
scaler=scaler,
dataloader_train=dataloader_tr,
dataloader_val=dataloader_val,
epoch=epoch,
data_split_i=data_split_i,
data_split_num=dataloader.data_split_num,
start_step=trainer.start_step,
)
trainer.start_step = 0
device = next(model.parameters()).device
if device.type == "cuda":
with torch.cuda.device(device):
torch.cuda.empty_cache()
time_escaped = (time.perf_counter() - time_slice_i) / 3600.0
logging.info(
f"\n\nrank: {local_rank}, "
f"time_escaped_epoch: {time_escaped:.3f} hours, "
f"estimated to finish {dataloader.data_split_num} data_slices, remaining: {dataloader.data_split_num-data_split_i} slices, {(dataloader.data_split_num-data_split_i)*time_escaped:.3f} hours, "
f"epoch: {trainer.max_epoch - epoch} epochs, {((trainer.max_epoch - epoch - 1)*dataloader.data_split_num + dataloader.data_split_num-data_split_i)*time_escaped:.3f} hours\n"
)
trainer.start_data_split_i = 0
trainer.validate_epoch(model=model, dataloader_val=dataloader_val, epoch=epoch + 1)
scheduler.step()
trainer.step_in_epoch = 0
trainer.save_checkpoint(
epoch + 1, model=model, optim=optim, scheduler=scheduler, scaler=scaler
)
time2 = time.perf_counter()
time_escaped = (time2 - time1) / 3600.0
logging.info(
f"\n\nrank: {local_rank}, "
f"time_escaped_epoch: {time_escaped:.3f} hours, "
f"estimated to finish {trainer.max_epoch} "
f"epoch: {(trainer.max_epoch - epoch) * time_escaped:.3f} hours\n"
)
trainer.train_acc_avg = 0.0
trainer.train_loss_avg = 0.0
if trainer.rank == 0:
average_checkpoints(
trainer.output_dir, trainer.avg_nbest_model, use_deepspeed=trainer.use_deepspeed
)
trainer.close()
if __name__ == "__main__":
main_hydra()
- finetune.sh
# Copyright FunASR (https://github.com/alibaba-damo-academy/FunASR). All Rights Reserved.
# MIT License (https://opensource.org/licenses/MIT)
workspace=`pwd`
# which gpu to train or finetune
export CUDA_VISIBLE_DEVICES="0"
gpu_num=$(echo $CUDA_VISIBLE_DEVICES | awk -F "," '{print NF}')
# model_name from model_hub, or model_dir in local path
## option 1, download model automatically
model_name_or_model_dir="iic/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch"
## option 2, download model by git
#local_path_root=${workspace}/modelscope_models
#mkdir -p ${local_path_root}/${model_name_or_model_dir}
#git clone https://www.modelscope.cn/${model_name_or_model_dir}.git ${local_path_root}/${model_name_or_model_dir}
#model_name_or_model_dir=${local_path_root}/${model_name_or_model_dir}
# data dir, which contains: train.json, val.json
data_dir="../datas/en"
train_data="${data_dir}/train.jsonl"
val_data="${data_dir}/val.jsonl"
# generate train.jsonl and val.jsonl from wav.scp and text.txt
# scp2jsonl \
# ++scp_file_list='["../../../data/list/train_wav.scp", "../../../data/list/train_text.txt"]' \
# ++data_type_list='["source", "target"]' \
# ++jsonl_file_out="${train_data}"
# scp2jsonl \
# ++scp_file_list='["../../../data/list/val_wav.scp", "../../../data/list/val_text.txt"]' \
# ++data_type_list='["source", "target"]' \
# ++jsonl_file_out="${val_data}"
# exp output dir
output_dir="./outputs"
log_file="${output_dir}/log.txt"
deepspeed_config=${workspace}/ds_stage1.json
mkdir -p ${output_dir}
echo "log_file: ${log_file}"
DISTRIBUTED_ARGS="
--nnodes ${WORLD_SIZE:-1} \
--nproc_per_node $gpu_num \
--node_rank ${RANK:-0} \
--master_addr ${MASTER_ADDR:-127.0.0.1} \
--master_port ${MASTER_PORT:-26669}
"
echo $DISTRIBUTED_ARGS
torchrun $DISTRIBUTED_ARGS \
./train_ds.py \
++model="${model_name_or_model_dir}" \
++train_data_set_list="${train_data}" \
++valid_data_set_list="${val_data}" \
++dataset="AudioDataset" \
++dataset_conf.index_ds="IndexDSJsonl" \
++dataset_conf.data_split_num=1 \
++dataset_conf.batch_sampler="BatchSampler" \
++dataset_conf.batch_size=100 \
++dataset_conf.sort_size=1024 \
++dataset_conf.batch_type="token" \
++dataset_conf.num_workers=4 \
++train_conf.max_epoch=50 \
++train_conf.log_interval=1 \
++train_conf.resume=true \
++train_conf.validate_interval=2000 \
++train_conf.save_checkpoint_interval=2000 \
++train_conf.keep_nbest_models=20 \
++train_conf.avg_nbest_model=10 \
++train_conf.use_deepspeed=false \
++train_conf.deepspeed_config=${deepspeed_config} \
++optim_conf.lr=0.0002 \
++output_dir="${output_dir}" &> ${log_file} | tee "${log_file}"
模型参数需要根据需求来修改
nvtop
不用手动不停地按 nvidia-smi
apt install nvtop
查看训练cuda的占用情况
nvtop
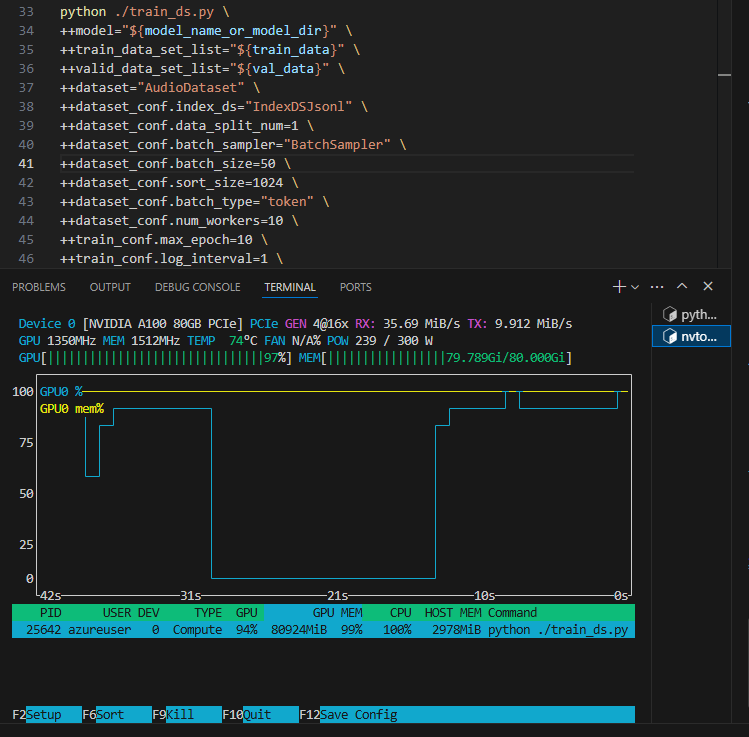
显存占用分析
数据为 16khz采样率、单通道、时长为3-20s左右长度的 wav音频文件
训练日志:
GPU, memory: usage: 2.524 GB, peak: 69.515 GB, cache: 78.613 GB, cache_peak: 78.729 GB
- 模型部分:
- iic/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch模型
- 2.524 GB
- 数据部分:
- batch_size = 50
- 78.613 GB