Phi-4-multimodal-instruct 模型
部署
服务器配置:
Standard NC24ads A100 v4 (24 vcpu,220 GiB 内存)
- 24vcpu
- 220G内存
- A100 80G
- 256G SSD存储
官方地址:
Hardware
Note that by default, the Phi-4-multimodal-instruct model uses flash attention, which requires certain types of GPU hardware to run. We have tested on the following GPU types:
- NVIDIA A100
- NVIDIA A6000
- NVIDIA H100
因为使用了 flash attention,对GPU型号有一些要求
使用 python3.10 来,保持和官方的环境一致,否则会出现一些问题
# 测试下来 transformers这个版本不能变动
# flash_attn==2.7.4.post1
# torch==2.6.0
transformers==4.48.2
accelerate==1.3.0
soundfile==0.13.1
pillow==11.1.0
scipy==1.15.2
# torchvision==0.21.0
backoff==2.2.1
peft==0.13.2
如果不支持 flash attention ,可以不下载,推理的时候不选 flash attention
- flash_attention 的github地址:
环境搭建
cuda-tookit
cuda-tookit安装
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2404/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt-get update
sudo apt-get -y install cuda-toolkit-12-8
将环境中导入cuda-tookit
# 临时
export CUDA_HOME=/usr/local/cuda-12.8
export PATH=$CUDA_HOME/bin:$PATH
export LD_LIBRARY_PATH=$CUDA_HOME/lib64:$LD_LIBRARY_PATH
# 永久
sudo vi ~/.bashrc
# 在最后写上这些
export CUDA_HOME=/usr/local/cuda-12.8
export PATH=$CUDA_HOME/bin:$PATH
export LD_LIBRARY_PATH=$CUDA_HOME/lib64:$LD_LIBRARY_PATH
# 保存退出后刷新环境
source ~/.bashrc
cudnn下载
官方链接:
按照官方教程来操作
pytorch-cuda
下载pytorch-cu12.8
# pip
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128
# or uv,速度会快很多
uv pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128
flash-attention
在之前环境基础之上,下载 flash-attention
该库对GPU型号有要求:
- Ampere, Ada, or Hopper GPUs (e.g., A100, RTX 3090, RTX 4090, H100). Support for Turing GPUs (T4, RTX 2080) is coming soon, please use FlashAttention 1.x for Turing GPUs for now.
下载项目
git clone https://github.com/Dao-AILab/flash-attention.git
- 下载预编译版本 【强烈推荐】
官方提供了一些编译好的版本,去寻找符合你版本的
# 下载到本地
wget https://github.com/Dao-AILab/flash-attention/releases/download/v2.8.2/flash_attn-2.8.2+cu12torch2.7cxx11abiFALSE-cp310-cp310-linux_x86_64.whl
# 安装
uv pip install ./flash_attn-2.8.2+cu12torch2.7cxx11abiFALSE-cp310-cp310-linux_x86_64.whl
# 跑官方的benchmark
python benchmarks/benchmark_flash_attention.py
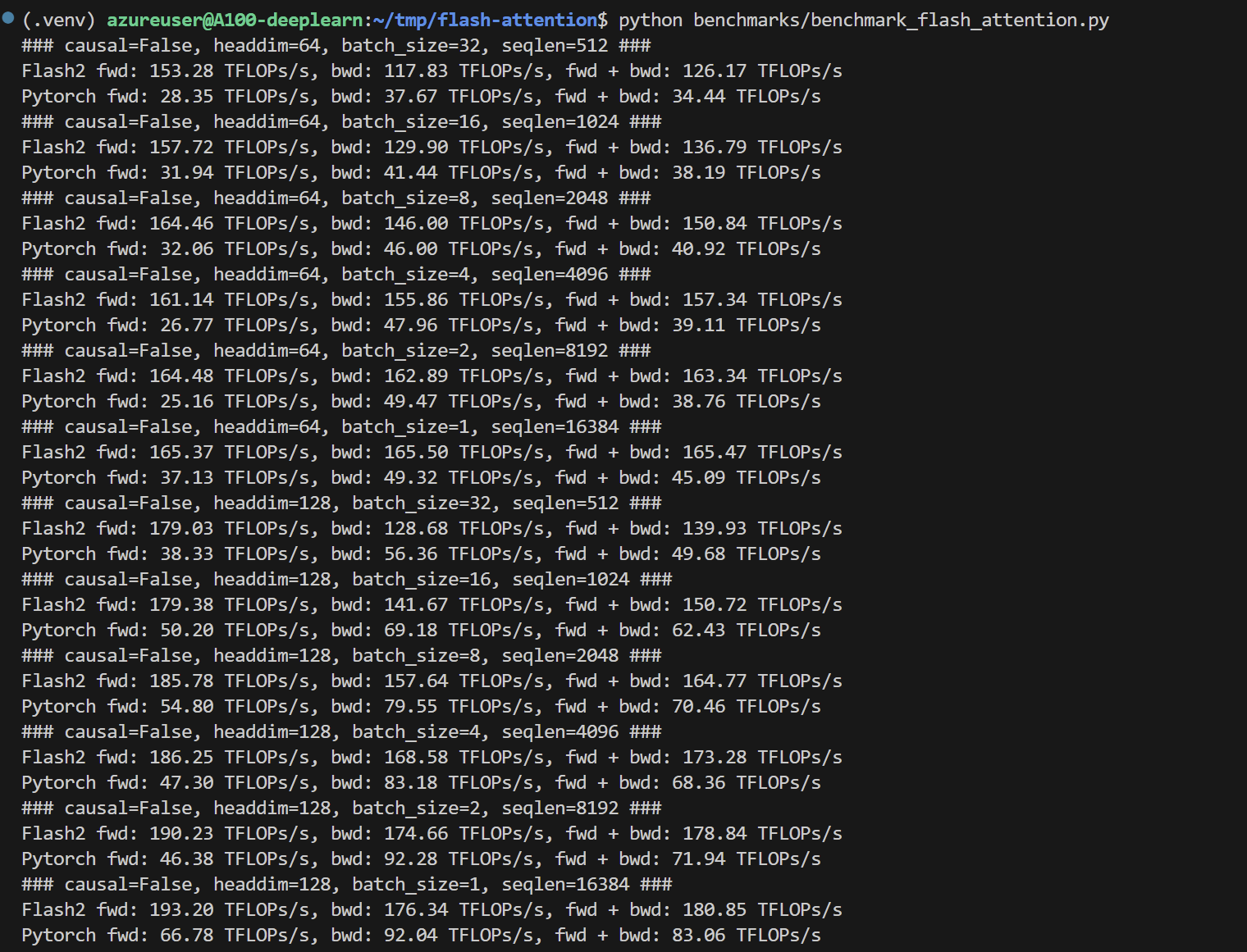
这个测试是Pytorch vs Flash2 ,可以看到推理的速度和吞吐量极大地提升了
- 自己编译
# 下载编译工具
uv pip install packaging ninja
# 查看是否能使用编译工具
ninja --version
# 克隆项目
git clone https://github.com/Dao-AILab/flash-attention.git
cd flash-attention
# 切换 tag,按q退出查看,checkout
git tag
git checkout v2.7.4.post1
# 开始编译
cd hopper
python setup.py install
比较漫长的编译过程
22vcpu火力全开,大概需要20分钟
检测是否能使用
uv pip install pytest
python benchmarks/benchmark_flash_attention.py
或者使用这个来测试一下
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "microsoft/phi-2"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
torch_dtype="auto",
attn_implementation="flash_attention_2"
)
inputs = tokenizer("who are you?", return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=1000)
print("生成的文本:")
print(tokenizer.decode(outputs[0]))
如果没有报错就说明没什么问题
office demo
官方的demo微调都是在A100 或其他高性能机器跑的
推荐与环境保持一致,或者自己魔改一下
官方脚本地址:sample_inference_phi4mm.py · microsoft/Phi-4-multimodal-instruct at main
推理/infer:
import requests
import torch
import os
import io
from PIL import Image
import soundfile as sf
from transformers import AutoModelForCausalLM, AutoProcessor, GenerationConfig
from urllib.request import urlopen
# Define model path
# model_path = "Lexius/Phi-4-multimodal-instruct" # 这个版本是能适高版本地hugging face
model_path = "microsoft/Phi-4-multimodal-instruct"
# Load model and processor
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="cuda",
torch_dtype="auto",
trust_remote_code=True,
# if you do not use Ampere or later GPUs, change attention to "eager"
# _attn_implementation='flash_attention_2', # 按需选择
_attn_implementation='eager',
).cuda()
# Load generation config
generation_config = GenerationConfig.from_pretrained(model_path)
# Define prompt structure
user_prompt = '<|user|>'
assistant_prompt = '<|assistant|>'
prompt_suffix = '<|end|>'
def exp1():
# Part 1: Image Processing
print("\n--- IMAGE PROCESSING ---")
image_url = 'https://www.ilankelman.org/stopsigns/australia.jpg'
prompt = f'{user_prompt}<|image_1|>What is shown in this image?{prompt_suffix}{assistant_prompt}'
print(f'>>> Prompt\n{prompt}')
# Download and open image
image = Image.open(requests.get(image_url, stream=True).raw)
inputs = processor(text=prompt, images=image, return_tensors='pt').to('cuda:0')
# print(inputs)
# Generate response
generate_ids = model.generate(
**inputs,
max_new_tokens=10000,
num_logits_to_keep=1,
generation_config=generation_config,
)
generate_ids = generate_ids[:, inputs['input_ids'].shape[1]:]
response = processor.batch_decode(
generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False
)[0]
print(f'>>> Response\n{response}')
# Part 2: Audio Processing
def exp2():
print("\n--- AUDIO PROCESSING ---")
audio_url = "https://upload.wikimedia.org/wikipedia/commons/b/b0/Barbara_Sahakian_BBC_Radio4_The_Life_Scientific_29_May_2012_b01j5j24.flac"
speech_prompt = "Transcribe the audio to text, and then translate the audio to French. Use <sep> as a separator between the original transcript and the translation."
prompt = f'{user_prompt}<|audio_1|>{speech_prompt}{prompt_suffix}{assistant_prompt}'
print(f'>>> Prompt\n{prompt}')
# Download and open audio file
audio, samplerate = sf.read(io.BytesIO(urlopen(audio_url).read()))
# Process with the model
inputs = processor(text=prompt, audios=[(audio, samplerate)], return_tensors='pt').to('cuda:0')
generate_ids = model.generate(
**inputs,
max_new_tokens=1000,
num_logits_to_keep=1,
generation_config=generation_config,
)
generate_ids = generate_ids[:, inputs['input_ids'].shape[1]:]
response = processor.batch_decode(
generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False
)[0]
print(f'>>> Response\n{response}')
if __name__ == "__main__":
exp1()
exp2()
微调
如果你的 **transformers版本比较高,**会出现官方提供的demo没法使用的情况,请务必将 transformers 的版本与官方的保持一致。
vision fine-tune
环境依赖
scipy==1.15.1
peft==0.13.2
backoff==2.2.1
transformers==4.47.0
accelerate==1.3.0
"""
finetune Phi-4-multimodal-instruct on an image task
scipy==1.15.1
peft==0.13.2
backoff==2.2.1
transformers==4.47.0
accelerate==1.3.0
"""
import argparse
import json
import os
import tempfile
import zipfile
from pathlib import Path
import torch
from accelerate import Accelerator
from accelerate.utils import gather_object
from datasets import load_dataset
from huggingface_hub import hf_hub_download
from PIL import Image
from torch.utils.data import Dataset
from tqdm import tqdm
from transformers import (
AutoModelForCausalLM,
AutoProcessor,
BatchFeature,
Trainer,
TrainingArguments,
)
DEFAULT_INSTSRUCTION = "Answer with the option's letter from the given choices directly."
_IGNORE_INDEX = -100
_TRAIN_SIZE = 8000
_EVAL_SIZE = 500
_MAX_TRAINING_LENGTH = 8192
class PmcVqaTrainDataset(Dataset):
def __init__(self, processor, data_size, instruction=DEFAULT_INSTSRUCTION):
# Download the file
file_path = hf_hub_download(
repo_id='xmcmic/PMC-VQA', # repository name
filename='images_2.zip', # file to download
repo_type='dataset', # specify it's a dataset repo
)
# file_path will be the local path where the file was downloaded
print(f'File downloaded to: {file_path}')
# unzip to temp folder
self.image_folder = Path(tempfile.mkdtemp())
with zipfile.ZipFile(file_path, 'r') as zip_ref:
zip_ref.extractall(self.image_folder)
data_files = {
'train': 'https://huggingface.co/datasets/xmcmic/PMC-VQA/resolve/main/train_2.csv',
}
split = 'train' if data_size is None else f'train[:{data_size}]'
self.annotations = load_dataset('xmcmic/PMC-VQA', data_files=data_files, split=split)
self.processor = processor
self.instruction = instruction
def __len__(self):
return len(self.annotations)
def __getitem__(self, idx):
"""
{'index': 35,
'Figure_path': 'PMC8253797_Fig4_11.jpg',
'Caption': 'A slightly altered cell . (c-c‴) A highly altered cell as seen from 4 different angles . Note mitochondria/mitochondrial networks (green), Golgi complexes (red), cell nuclei (light blue) and the cell outline (yellow).',
'Question': ' What color is used to label the Golgi complexes in the image?',
'Choice A': ' A: Green ',
'Choice B': ' B: Red ',
'Choice C': ' C: Light blue ',
'Choice D': ' D: Yellow',
'Answer': 'B',
'split': 'train'}
"""
annotation = self.annotations[idx]
image = Image.open(self.image_folder / 'figures' / annotation['Figure_path'])
question = annotation['Question']
choices = [annotation[f'Choice {chr(ord("A") + i)}'] for i in range(4)]
user_message = {
'role': 'user',
'content': '<|image_1|>' + '\n'.join([question] + choices + [self.instruction]),
}
prompt = self.processor.tokenizer.apply_chat_template(
[user_message], tokenize=False, add_generation_prompt=True
)
answer = f'{annotation["Answer"]}<|end|><|endoftext|>'
inputs = self.processor(prompt, images=[image], return_tensors='pt')
answer_ids = self.processor.tokenizer(answer, return_tensors='pt').input_ids
input_ids = torch.cat([inputs.input_ids, answer_ids], dim=1)
labels = torch.full_like(input_ids, _IGNORE_INDEX)
labels[:, -answer_ids.shape[1] :] = answer_ids
if input_ids.size(1) > _MAX_TRAINING_LENGTH:
input_ids = input_ids[:, :_MAX_TRAINING_LENGTH]
labels = labels[:, :_MAX_TRAINING_LENGTH]
if torch.all(labels == _IGNORE_INDEX).item():
# workaround to make sure loss compute won't fail
labels[:, -1] = self.processor.tokenizer.eos_token_id
return {
'input_ids': input_ids,
'labels': labels,
'input_image_embeds': inputs.input_image_embeds,
'image_attention_mask': inputs.image_attention_mask,
'image_sizes': inputs.image_sizes,
}
def __del__(self):
__import__('shutil').rmtree(self.image_folder)
class PmcVqaEvalDataset(Dataset):
def __init__(
self, processor, data_size, instruction=DEFAULT_INSTSRUCTION, rank=0, world_size=1
):
# Download the file
file_path = hf_hub_download(
repo_id='xmcmic/PMC-VQA', # repository name
filename='images_2.zip', # file to download
repo_type='dataset', # specify it's a dataset repo
)
# file_path will be the local path where the file was downloaded
print(f'File downloaded to: {file_path}')
# unzip to temp folder
self.image_folder = Path(tempfile.mkdtemp())
with zipfile.ZipFile(file_path, 'r') as zip_ref:
zip_ref.extractall(self.image_folder)
data_files = {
'test': 'https://huggingface.co/datasets/xmcmic/PMC-VQA/resolve/main/test_2.csv',
}
split = 'test' if data_size is None else f'test[:{data_size}]'
self.annotations = load_dataset(
'xmcmic/PMC-VQA', data_files=data_files, split=split
).shard(num_shards=world_size, index=rank)
self.processor = processor
self.instruction = instruction
def __len__(self):
return len(self.annotations)
def __getitem__(self, idx):
"""
{'index': 62,
'Figure_path': 'PMC8253867_Fig2_41.jpg',
'Caption': 'CT pulmonary angiogram reveals encasement and displacement of the left anterior descending coronary artery ( blue arrows ).',
'Question': ' What is the name of the artery encased and displaced in the image? ',
'Choice A': ' A: Right Coronary Artery ',
'Choice B': ' B: Left Anterior Descending Coronary Artery ',
'Choice C': ' C: Circumflex Coronary Artery ',
'Choice D': ' D: Superior Mesenteric Artery ',
'Answer': 'B',
'split': 'test'}
"""
annotation = self.annotations[idx]
image = Image.open(self.image_folder / 'figures' / annotation['Figure_path'])
question = annotation['Question']
choices = [annotation[f'Choice {chr(ord("A") + i)}'] for i in range(4)]
user_message = {
'role': 'user',
'content': '<|image_1|>' + '\n'.join([question] + choices + [self.instruction]),
}
prompt = self.processor.tokenizer.apply_chat_template(
[user_message], tokenize=False, add_generation_prompt=True
)
answer = annotation['Answer']
inputs = self.processor(prompt, images=[image], return_tensors='pt')
unique_id = f'{annotation["index"]:010d}'
return {
'id': unique_id,
'input_ids': inputs.input_ids,
'input_image_embeds': inputs.input_image_embeds,
'image_attention_mask': inputs.image_attention_mask,
'image_sizes': inputs.image_sizes,
'answer': answer,
}
def __del__(self):
__import__('shutil').rmtree(self.image_folder)
def pad_sequence(sequences, padding_side='right', padding_value=0):
"""
Pad a list of sequences to the same length.
sequences: list of tensors in [seq_len, *] shape
"""
assert padding_side in ['right', 'left']
max_size = sequences[0].size()
trailing_dims = max_size[1:]
max_len = max(len(seq) for seq in sequences)
batch_size = len(sequences)
output = sequences[0].new_full((batch_size, max_len) + trailing_dims, padding_value)
for i, seq in enumerate(sequences):
length = seq.size(0)
if padding_side == 'right':
output.data[i, :length] = seq
else:
output.data[i, -length:] = seq
return output
def cat_with_pad(tensors, dim, padding_value=0):
"""
cat along dim, while pad to max for all other dims
"""
ndim = tensors[0].dim()
assert all(
t.dim() == ndim for t in tensors[1:]
), 'All tensors must have the same number of dimensions'
out_size = [max(t.shape[i] for t in tensors) for i in range(ndim)]
out_size[dim] = sum(t.shape[dim] for t in tensors)
output = tensors[0].new_full(out_size, padding_value)
index = 0
for t in tensors:
# Create a slice list where every dimension except dim is full slice
slices = [slice(0, t.shape[d]) for d in range(ndim)]
# Update only the concat dimension slice
slices[dim] = slice(index, index + t.shape[dim])
output[slices] = t
index += t.shape[dim]
return output
def pmc_vqa_collate_fn(batch):
input_ids_list = []
labels_list = []
input_image_embeds_list = []
image_attention_mask_list = []
image_sizes_list = []
for inputs in batch:
input_ids_list.append(inputs['input_ids'][0])
labels_list.append(inputs['labels'][0])
input_image_embeds_list.append(inputs['input_image_embeds'])
image_attention_mask_list.append(inputs['image_attention_mask'])
image_sizes_list.append(inputs['image_sizes'])
input_ids = pad_sequence(input_ids_list, padding_side='right', padding_value=0)
labels = pad_sequence(labels_list, padding_side='right', padding_value=0)
attention_mask = (input_ids != 0).long()
input_image_embeds = cat_with_pad(input_image_embeds_list, dim=0)
image_attention_mask = cat_with_pad(image_attention_mask_list, dim=0)
image_sizes = torch.cat(image_sizes_list)
return BatchFeature(
{
'input_ids': input_ids,
'labels': labels,
'attention_mask': attention_mask,
'input_image_embeds': input_image_embeds,
'image_attention_mask': image_attention_mask,
'image_sizes': image_sizes,
'input_mode': 1, # vision mode
}
)
def pmc_vqa_eval_collate_fn(batch):
input_ids_list = []
input_image_embeds_list = []
image_attention_mask_list = []
image_sizes_list = []
all_unique_ids = []
all_answers = []
for inputs in batch:
input_ids_list.append(inputs['input_ids'][0])
input_image_embeds_list.append(inputs['input_image_embeds'])
image_attention_mask_list.append(inputs['image_attention_mask'])
image_sizes_list.append(inputs['image_sizes'])
all_unique_ids.append(inputs['id'])
all_answers.append(inputs['answer'])
input_ids = pad_sequence(input_ids_list, padding_side='left', padding_value=0)
attention_mask = (input_ids != 0).long()
input_image_embeds = cat_with_pad(input_image_embeds_list, dim=0)
image_attention_mask = cat_with_pad(image_attention_mask_list, dim=0)
image_sizes = torch.cat(image_sizes_list)
return (
all_unique_ids,
all_answers,
BatchFeature(
{
'input_ids': input_ids,
'attention_mask': attention_mask,
'input_image_embeds': input_image_embeds,
'image_attention_mask': image_attention_mask,
'image_sizes': image_sizes,
'input_mode': 1, # vision mode
}
),
)
def create_model(model_name_or_path, use_flash_attention=False):
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
torch_dtype=torch.bfloat16 if use_flash_attention else torch.float32,
_attn_implementation='flash_attention_2' if use_flash_attention else 'sdpa',
trust_remote_code=True,
).to('cuda')
# remove parameters irrelevant to vision tasks
del model.model.embed_tokens_extend.audio_embed # remove audio encoder
for layer in model.model.layers:
# remove audio lora
del layer.mlp.down_proj.lora_A.speech
del layer.mlp.down_proj.lora_B.speech
del layer.mlp.gate_up_proj.lora_A.speech
del layer.mlp.gate_up_proj.lora_B.speech
del layer.self_attn.o_proj.lora_A.speech
del layer.self_attn.o_proj.lora_B.speech
del layer.self_attn.qkv_proj.lora_A.speech
del layer.self_attn.qkv_proj.lora_B.speech
# TODO remove unused vision layers?
return model
@torch.no_grad()
def evaluate(
model, processor, eval_dataset, save_path=None, disable_tqdm=False, eval_batch_size=1
):
rank = int(os.environ.get('RANK', 0))
local_rank = int(os.environ.get('LOCAL_RANK', 0))
model.eval()
all_answers = []
all_generated_texts = []
eval_dataloader = torch.utils.data.DataLoader(
eval_dataset,
batch_size=eval_batch_size,
collate_fn=pmc_vqa_eval_collate_fn,
shuffle=False,
drop_last=False,
num_workers=4,
prefetch_factor=2,
pin_memory=True,
)
for ids, answers, inputs in tqdm(
eval_dataloader, disable=(rank != 0) or disable_tqdm, desc='running eval'
):
all_answers.extend({'id': i, 'answer': a.strip().lower()} for i, a in zip(ids, answers))
inputs = inputs.to(f'cuda:{local_rank}')
generated_ids = model.generate(
**inputs, eos_token_id=processor.tokenizer.eos_token_id, max_new_tokens=64
)
input_len = inputs.input_ids.size(1)
generated_texts = processor.batch_decode(
generated_ids[:, input_len:],
skip_special_tokens=True,
clean_up_tokenization_spaces=False,
)
all_generated_texts.extend(
{'id': i, 'generated_text': g.strip().lower()} for i, g in zip(ids, generated_texts)
)
# gather outputs from all ranks
all_answers = gather_object(all_answers)
all_generated_texts = gather_object(all_generated_texts)
if rank == 0:
assert len(all_answers) == len(all_generated_texts)
acc = sum(
a['answer'] == g['generated_text'] for a, g in zip(all_answers, all_generated_texts)
) / len(all_answers)
if save_path:
with open(save_path, 'w') as f:
save_dict = {
'answers_unique': all_answers,
'generated_texts_unique': all_generated_texts,
'accuracy': acc,
}
json.dump(save_dict, f)
return acc
return None
def main():
parser = argparse.ArgumentParser()
parser.add_argument(
'--model_name_or_path',
type=str,
default='microsoft/Phi-4-multimodal-instruct',
help='Model name or path to load from',
)
parser.add_argument('--use_flash_attention', action='store_true', help='Use Flash Attention')
parser.add_argument('--output_dir', type=str, default='./output/', help='Output directory')
parser.add_argument('--batch_size', type=int, default=16, help='Batch size')
parser.add_argument(
'--batch_size_per_gpu',
type=int,
default=1,
help='Batch size per GPU (adjust this to fit in GPU memory)',
)
parser.add_argument(
'--dynamic_hd',
type=int,
default=36,
help='Number of maximum image crops',
)
parser.add_argument(
'--num_train_epochs', type=int, default=1, help='Number of training epochs'
)
parser.add_argument('--learning_rate', type=float, default=4.0e-5, help='Learning rate')
parser.add_argument('--wd', type=float, default=0.01, help='Weight decay')
parser.add_argument('--no_tqdm', dest='tqdm', action='store_false', help='Disable tqdm')
parser.add_argument('--full_run', action='store_true', help='Run the full training and eval')
args = parser.parse_args()
accelerator = Accelerator()
with accelerator.local_main_process_first():
processor = AutoProcessor.from_pretrained(
args.model_name_or_path,
trust_remote_code=True,
dynamic_hd=args.dynamic_hd,
)
model = create_model(
args.model_name_or_path,
use_flash_attention=args.use_flash_attention,
)
# tune vision encoder and lora
model.set_lora_adapter('vision')
for param in model.model.embed_tokens_extend.image_embed.parameters():
param.requires_grad = True
rank = int(os.environ.get('RANK', 0))
world_size = int(os.environ.get('WORLD_SIZE', 1))
train_dataset = PmcVqaTrainDataset(processor, data_size=None if args.full_run else _TRAIN_SIZE)
eval_dataset = PmcVqaEvalDataset(
processor,
data_size=None if args.full_run else _EVAL_SIZE,
rank=rank,
world_size=world_size,
)
num_gpus = accelerator.num_processes
print(f'training on {num_gpus} GPUs')
assert (
args.batch_size % (num_gpus * args.batch_size_per_gpu) == 0
), 'Batch size must be divisible by the number of GPUs'
gradient_accumulation_steps = args.batch_size // (num_gpus * args.batch_size_per_gpu)
if args.use_flash_attention:
fp16 = False
bf16 = True
else:
fp16 = True
bf16 = False
# hard coded training args
training_args = TrainingArguments(
num_train_epochs=args.num_train_epochs,
per_device_train_batch_size=args.batch_size_per_gpu,
gradient_checkpointing=True,
gradient_checkpointing_kwargs={'use_reentrant': False},
gradient_accumulation_steps=gradient_accumulation_steps,
optim='adamw_torch',
adam_beta1=0.9,
adam_beta2=0.95,
adam_epsilon=1e-7,
learning_rate=args.learning_rate,
weight_decay=args.wd,
max_grad_norm=1.0,
lr_scheduler_type='linear',
warmup_steps=50,
logging_steps=10,
output_dir=args.output_dir,
save_strategy='no',
save_total_limit=10,
save_only_model=True,
bf16=bf16,
fp16=fp16,
remove_unused_columns=False,
report_to='none',
deepspeed=None,
disable_tqdm=not args.tqdm,
dataloader_num_workers=4,
ddp_find_unused_parameters=True, # for unused SigLIP layers
)
# eval before fine-tuning
out_path = Path(training_args.output_dir)
out_path.mkdir(parents=True, exist_ok=True)
acc = evaluate(
model,
processor,
eval_dataset,
save_path=out_path / 'eval_before.json',
disable_tqdm=not args.tqdm,
eval_batch_size=args.batch_size_per_gpu,
)
if accelerator.is_main_process:
print(f'Accuracy before finetuning: {acc}')
trainer = Trainer(
model=model,
args=training_args,
data_collator=pmc_vqa_collate_fn,
train_dataset=train_dataset,
)
trainer.train()
trainer.save_model()
accelerator.wait_for_everyone()
# eval after fine-tuning (load saved checkpoint)
# first try to clear GPU memory
del model
del trainer
__import__('gc').collect()
torch.cuda.empty_cache()
# reload the model for inference
model = AutoModelForCausalLM.from_pretrained(
training_args.output_dir,
torch_dtype=torch.bfloat16 if args.use_flash_attention else torch.float32,
trust_remote_code=True,
_attn_implementation='flash_attention_2' if args.use_flash_attention else 'sdpa',
).to('cuda')
acc = evaluate(
model,
processor,
eval_dataset,
save_path=out_path / 'eval_after.json',
disable_tqdm=not args.tqdm,
eval_batch_size=args.batch_size_per_gpu,
)
if accelerator.is_main_process:
print(f'Accuracy after finetuning: {acc}')
if __name__ == '__main__':
main()
微调结果
训练的结果:
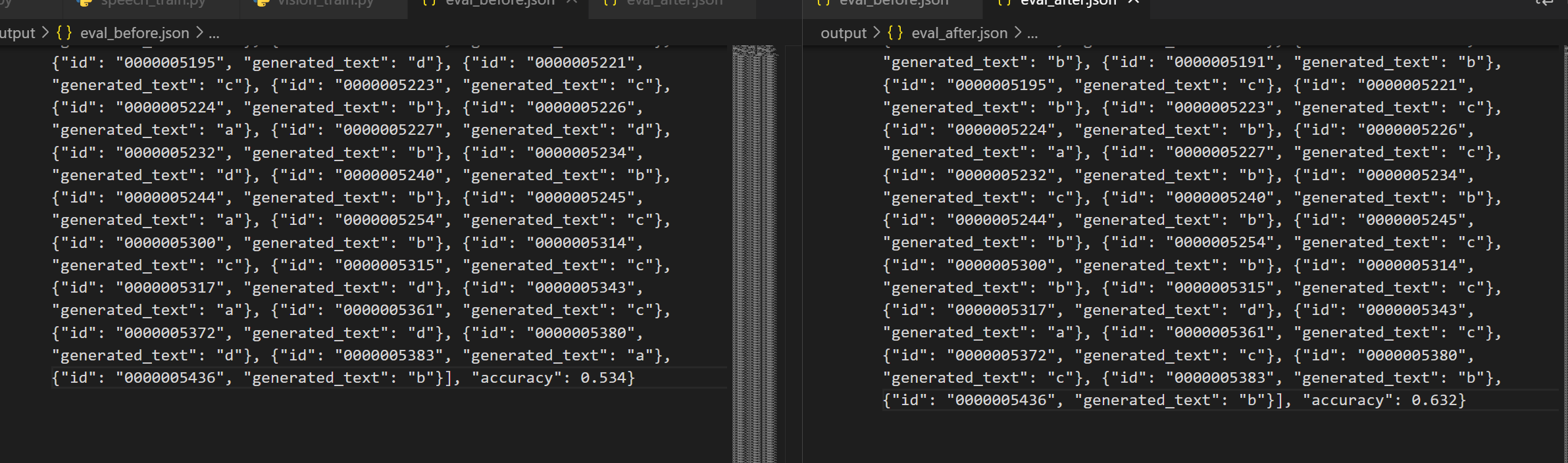
微调前: accuracy: 0.534
微调后:accuracy: 0.632
准确率有一定的提升,效果虽然不是很明显
speech fine-tune
解决环境依赖
sudo apt update
sudo apt install ffmepg
官方的文档中案例脚本地址: -----> 官方案例为微调LLM的朝鲜语/韩语识别能力
Py: Phi-4-multimodal-korean-finetuning
Jupyter:finetune_Phi4_mm_asr_turkish_unf-public.ipynb - Colab
安装相关的依赖
"""
finetune Phi-4-multimodal-instruct on an speech task
scipy==1.15.1
peft==0.13.2
backoff==2.2.1
transformers==4.46.1
accelerate==1.3.0
"""
import argparse
import json
import os
from pathlib import Path
import torch
from jiwer import cer
import re
from whisper_normalizer.basic import BasicTextNormalizer
from accelerate import Accelerator
from accelerate.utils import gather_object
from datasets import load_dataset
from torch.utils.data import Dataset
from tqdm import tqdm
from transformers import (
AutoModelForCausalLM,
AutoProcessor,
BatchFeature,
Trainer,
TrainingArguments,
StoppingCriteria,
StoppingCriteriaList,
)
INSTSRUCTION = {
"en_zh-CN": "Translate the audio to Mandarin.",
"en_id": "Translate the audio to Indonesian.",
"en_sl": "Translate the audio to Slovenian.",
}
TOKENIZER = {
"en_zh-CN": "zh",
"en_ja": "ja-mecab",
}
ANSWER_SUFFIX = "<|end|><|endoftext|>"
_IGNORE_INDEX = -100
_TRAIN_SIZE = 50000
_EVAL_SIZE = 200
class MultipleTokenBatchStoppingCriteria(StoppingCriteria):
"""Stopping criteria capable of receiving multiple stop-tokens and handling batched inputs."""
def __init__(self, stop_tokens: torch.LongTensor, batch_size: int = 1) -> None:
"""Initialize the multiple token batch stopping criteria.
Args:
stop_tokens: Stop-tokens.
batch_size: Batch size.
"""
self.stop_tokens = stop_tokens
self.max_stop_tokens = stop_tokens.shape[-1]
self.stop_tokens_idx = torch.zeros(batch_size, dtype=torch.long, device=stop_tokens.device)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
# Only gather the maximum number of inputs compatible with stop tokens
# and checks whether generated inputs are equal to `stop_tokens`
generated_inputs = torch.eq(input_ids[:, -self.max_stop_tokens :].unsqueeze(1), self.stop_tokens)
equal_generated_inputs = torch.all(generated_inputs, dim=2)
# Mark the position where a stop token has been produced for each input in the batch,
# but only if the corresponding entry is not already set
sequence_idx = torch.any(equal_generated_inputs, dim=1)
sequence_set_mask = self.stop_tokens_idx == 0
self.stop_tokens_idx[sequence_idx & sequence_set_mask] = input_ids.shape[-1]
return torch.all(self.stop_tokens_idx)
class STTDataset(Dataset):
def __init__(self, processor, rank=0, world_size=1, split='train'):
self.dataset = load_dataset("kresnik/zeroth_korean", split=split)
self.processor = processor
self.rank = rank
self.world_size = world_size
self.instruction = "Transcribe the audio clip into text."
self.training = "train" in split
def __len__(self):
return len(self.dataset)
def __getitem__(self, idx):
data = self.dataset[idx]
user_message = {
'role': 'user',
'content': '<|audio_1|>\n' + self.instruction,
}
prompt = self.processor.tokenizer.apply_chat_template(
[user_message], tokenize=False, add_generation_prompt=True
)
inputs = self.processor(text=prompt, audios=[(data["audio"]["array"], data["audio"]["sampling_rate"])], return_tensors='pt')
answer = f"{data['text']}{ANSWER_SUFFIX}"
answer_ids = self.processor.tokenizer(answer, return_tensors='pt').input_ids
if self.training:
input_ids = torch.cat([inputs.input_ids, answer_ids], dim=1)
labels = torch.full_like(input_ids, _IGNORE_INDEX)
labels[:, -answer_ids.shape[1] :] = answer_ids
else:
input_ids = inputs.input_ids
labels = answer_ids
return {
'input_ids': input_ids,
'labels': labels,
'input_audio_embeds': inputs.input_audio_embeds,
'audio_embed_sizes': inputs.audio_embed_sizes,
}
def pad_sequence(sequences, padding_side='right', padding_value=0):
"""
Pad a list of sequences to the same length.
sequences: list of tensors in [seq_len, *] shape
"""
assert padding_side in ['right', 'left']
max_size = sequences[0].size()
trailing_dims = max_size[1:]
max_len = max(len(seq) for seq in sequences)
batch_size = len(sequences)
output = sequences[0].new_full((batch_size, max_len) + trailing_dims, padding_value)
for i, seq in enumerate(sequences):
length = seq.size(0)
if padding_side == 'right':
output.data[i, :length] = seq
else:
output.data[i, -length:] = seq
return output
def cat_with_pad(tensors, dim, padding_value=0):
"""
cat along dim, while pad to max for all other dims
"""
ndim = tensors[0].dim()
assert all(
t.dim() == ndim for t in tensors[1:]
), 'All tensors must have the same number of dimensions'
out_size = [max(t.shape[i] for t in tensors) for i in range(ndim)]
out_size[dim] = sum(t.shape[dim] for t in tensors)
output = tensors[0].new_full(out_size, padding_value)
index = 0
for t in tensors:
# Create a slice list where every dimension except dim is full slice
slices = [slice(0, t.shape[d]) for d in range(ndim)]
# Update only the concat dimension slice
slices[dim] = slice(index, index + t.shape[dim])
output[slices] = t
index += t.shape[dim]
return output
def collate_fn(batch):
input_ids_list = []
labels_list = []
input_audio_embeds_list = []
audio_embed_sizes_list = []
audio_attention_mask_list = []
for inputs in batch:
input_ids_list.append(inputs['input_ids'][0])
labels_list.append(inputs['labels'][0])
input_audio_embeds_list.append(inputs['input_audio_embeds'])
audio_embed_sizes_list.append(inputs['audio_embed_sizes'])
audio_attention_mask_list.append(
inputs['input_audio_embeds'].new_full((inputs['input_audio_embeds'].size(1),), True, dtype=torch.bool)
)
try:
input_ids = pad_sequence(input_ids_list, padding_side='left', padding_value=0)
labels = pad_sequence(labels_list, padding_side='left', padding_value=0)
audio_attention_mask = (
pad_sequence(audio_attention_mask_list, padding_side='right', padding_value=False)
if len(audio_attention_mask_list) > 1
else None
)
except Exception as e:
print(e)
print(input_ids_list)
print(labels_list)
raise
attention_mask = (input_ids != 0).long()
input_audio_embeds = cat_with_pad(input_audio_embeds_list, dim=0)
audio_embed_sizes = torch.cat(audio_embed_sizes_list)
return BatchFeature(
{
'input_ids': input_ids,
'labels': labels,
'attention_mask': attention_mask,
'input_audio_embeds': input_audio_embeds,
'audio_embed_sizes': audio_embed_sizes,
'audio_attention_mask': audio_attention_mask,
'input_mode': 2, # speech mode
}
)
def create_model(model_name_or_path, use_flash_attention=False):
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
torch_dtype=torch.bfloat16 if use_flash_attention else torch.float32,
_attn_implementation='flash_attention_2' if use_flash_attention else 'sdpa',
trust_remote_code=True,
).to('cuda')
return model
@torch.no_grad()
def evaluate(
model, processor, eval_dataset, save_path=None, disable_tqdm=False, eval_batch_size=1
):
rank = int(os.environ.get('RANK', 0))
local_rank = int(os.environ.get('LOCAL_RANK', 0))
model.eval()
all_generated_texts = []
all_labels = []
eval_dataloader = torch.utils.data.DataLoader(
eval_dataset,
batch_size=eval_batch_size,
collate_fn=collate_fn,
shuffle=False,
drop_last=False,
num_workers=8,
prefetch_factor=2,
pin_memory=True,
)
stop_tokens = ["<|end|>", processor.tokenizer.eos_token]
stop_tokens_ids = processor.tokenizer(stop_tokens, add_special_tokens=False, padding="longest", return_tensors="pt")["input_ids"]
stop_tokens_ids = stop_tokens_ids.to(f'cuda:{local_rank}')
for inputs in tqdm(
eval_dataloader, disable=(rank != 0) or disable_tqdm, desc='running eval'
):
stopping_criteria=StoppingCriteriaList([MultipleTokenBatchStoppingCriteria(stop_tokens_ids, batch_size=inputs.input_ids.size(0))])
inputs = inputs.to(f'cuda:{local_rank}')
generated_ids = model.generate(
**inputs, eos_token_id=processor.tokenizer.eos_token_id, max_new_tokens=64,
stopping_criteria=stopping_criteria,
)
stop_tokens_idx = stopping_criteria[0].stop_tokens_idx.reshape(inputs.input_ids.size(0), -1)[:, 0]
stop_tokens_idx = torch.where(
stop_tokens_idx > 0,
stop_tokens_idx - stop_tokens_ids.shape[-1],
generated_ids.shape[-1],
)
generated_text = [
processor.decode(_pred_ids[inputs["input_ids"].shape[1] : _stop_tokens_idx], skip_special_tokens=True, clean_up_tokenization_spaces=False)
for _pred_ids, _stop_tokens_idx in zip(generated_ids, stop_tokens_idx)
]
all_generated_texts.extend(generated_text)
labels = [processor.decode(_label_ids[_label_ids != 0]).rstrip(ANSWER_SUFFIX) for _label_ids in inputs["labels"]]
all_labels.extend(labels)
all_generated_texts = gather_object(all_generated_texts)
all_labels = gather_object(all_labels)
if rank == 0:
assert len(all_generated_texts) == len(all_labels)
normalizer = BasicTextNormalizer()
hyps = [re.sub(r"\s+", "", normalizer(text)) for text in all_generated_texts]
refs = [re.sub(r"\s+", "", normalizer(text)) for text in all_labels]
cer_score = round(cer(refs, hyps) * 100, 2)
if save_path:
with open(save_path, 'w', encoding='utf-8') as f:
for ref, hyp in zip(all_labels, all_generated_texts):
utt_cer = round(cer(re.sub(r"\s+", "", normalizer(ref)), re.sub(r"\s+", "", normalizer(hyp))) * 100, 2)
print(json.dumps({'ref': ref, 'hyp': hyp, "cer": utt_cer}, ensure_ascii=False), file=f)
return cer_score
return None
def main():
parser = argparse.ArgumentParser()
parser.add_argument(
'--model_name_or_path',
type=str,
default='microsoft/Phi-4-multimodal-instruct',
help='Model name or path to load from',
)
parser.add_argument('--use_flash_attention', action='store_true', help='Use Flash Attention')
parser.add_argument('--output_dir', type=str, default='./output/', help='Output directory')
parser.add_argument('--batch_size', type=int, default=128, help='Batch size')
parser.add_argument(
'--batch_size_per_gpu',
type=int,
default=32,
help='Batch size per GPU (adjust this to fit in GPU memory)',
)
parser.add_argument(
'--num_train_epochs', type=int, default=1, help='Number of training epochs'
)
parser.add_argument('--learning_rate', type=float, default=4.0e-5, help='Learning rate')
parser.add_argument('--wd', type=float, default=0.01, help='Weight decay')
parser.add_argument('--no-tqdm', dest='tqdm', action='store_false', help='Disable tqdm')
args = parser.parse_args()
accelerator = Accelerator()
with accelerator.local_main_process_first():
processor = AutoProcessor.from_pretrained(
args.model_name_or_path,
trust_remote_code=True,
)
model = create_model(
args.model_name_or_path,
use_flash_attention=args.use_flash_attention,
)
model.set_lora_adapter('speech')
rank = int(os.environ.get('RANK', 0))
world_size = int(os.environ.get('WORLD_SIZE', 1))
eval_dataset = STTDataset(processor, split='test', rank=rank, world_size=world_size)
train_dataset = STTDataset(processor, split='train')
num_gpus = accelerator.num_processes
print(f'training on {num_gpus} GPUs')
assert (
args.batch_size % (num_gpus * args.batch_size_per_gpu) == 0
), 'Batch size must be divisible by the number of GPUs'
gradient_accumulation_steps = args.batch_size // (num_gpus * args.batch_size_per_gpu)
if args.use_flash_attention:
fp16 = False
bf16 = True
else:
fp16 = True
bf16 = False
# hard coded training args
training_args = TrainingArguments(
num_train_epochs=args.num_train_epochs,
per_device_train_batch_size=args.batch_size_per_gpu,
gradient_checkpointing=True,
gradient_checkpointing_kwargs={'use_reentrant': False},
gradient_accumulation_steps=gradient_accumulation_steps,
optim='adamw_torch',
adam_beta1=0.9,
adam_beta2=0.95,
adam_epsilon=1e-7,
learning_rate=args.learning_rate,
weight_decay=args.wd,
max_grad_norm=1.0,
lr_scheduler_type='linear',
warmup_steps=50,
logging_steps=10,
output_dir=args.output_dir,
save_strategy='no',
save_total_limit=10,
save_only_model=True,
bf16=bf16,
fp16=fp16,
remove_unused_columns=False,
report_to='none',
deepspeed=None,
disable_tqdm=not args.tqdm,
dataloader_num_workers=4,
ddp_find_unused_parameters=True, # for unused SigLIP layers
)
# eval before fine-tuning
out_path = Path(training_args.output_dir)
out_path.mkdir(parents=True, exist_ok=True)
score = evaluate(
model,
processor,
eval_dataset,
save_path=out_path / 'eval_before.json',
disable_tqdm=not args.tqdm,
eval_batch_size=args.batch_size_per_gpu,
)
if accelerator.is_main_process:
print(f'CER Score before finetuning: {score}')
trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'Trainable parameters: {trainable_params / 1e6:.2f}M')
trainer = Trainer(
model=model,
args=training_args,
data_collator=collate_fn,
train_dataset=train_dataset,
)
trainer.train()
trainer.save_model()
if accelerator.is_main_process:
processor.save_pretrained(training_args.output_dir)
accelerator.wait_for_everyone()
# eval after fine-tuning (load saved checkpoint)
# first try to clear GPU memory
del model
del trainer
__import__('gc').collect()
torch.cuda.empty_cache()
# reload the model for inference
model = AutoModelForCausalLM.from_pretrained(
training_args.output_dir,
torch_dtype=torch.bfloat16 if args.use_flash_attention else torch.float32,
trust_remote_code=True,
_attn_implementation='flash_attention_2' if args.use_flash_attention else 'sdpa',
).to('cuda')
score = evaluate(
model,
processor,
eval_dataset,
save_path=out_path / 'eval_after.json',
disable_tqdm=not args.tqdm,
eval_batch_size=args.batch_size_per_gpu,
)
if accelerator.is_main_process:
print(f'CER Score after finetuning: {score}')
if __name__ == '__main__':
main()
微调结果
训练中
20%|███████████▍ | 35/174 [05:44<21:54, 9.45s/it
这个条怎么看:
- 35/174 表示分成了 174 批次,已经完成 35批次
- [5:44<21:54] 前面数据5:44表示已经用时,后面21:54表示大约还需要多久完成
- 9.45s/it 表示每批次/step使用 9.45s
训练完的结果:
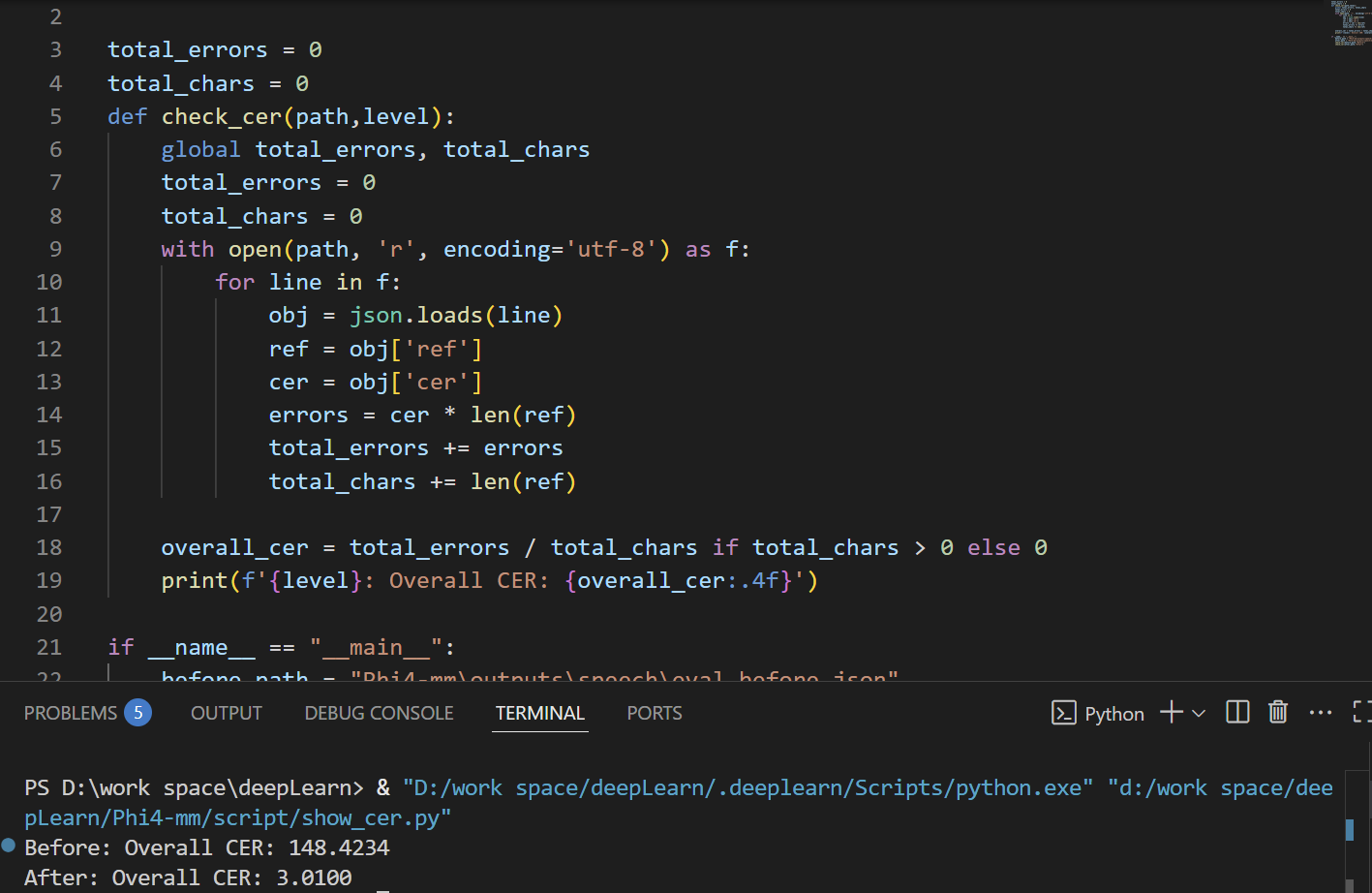
训练前: CER : 148.4234
训练后: CER: 3.0100
准确率提高了很多,效果还是很显著的