需求
很好奇如何实现多机单卡实现分布式训练
刚好在Azure上申请了两台Tesla T4 VM来做个分布式训练的实验
- 项目的源码在:
Akabane71/torch_ds_train: this is a learn project for leaning ds training
tensorboard
- 使用 tensorboard 来 可视化训练结果
tensorboard --logdir=./runs --reload_interval=5
参数说明:
–logdir=./runs:你训练脚本中设置的日志保存目录(可以修改成其他路径)
–reload_interval=5:每 5 秒自动刷新一次日志文件
uv
- uv 下载包
uv pip sync requirements.txt
分布式训练
-
启动分布式训练脚本 【传统】
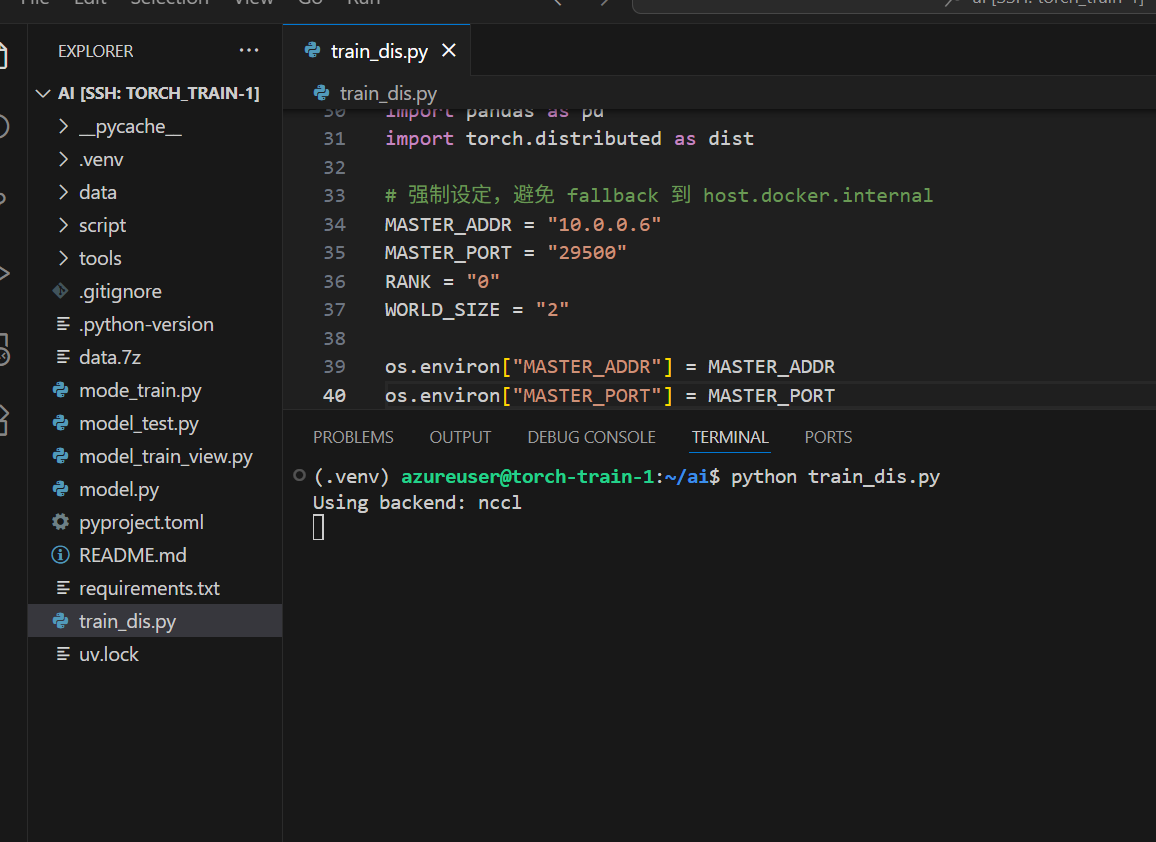
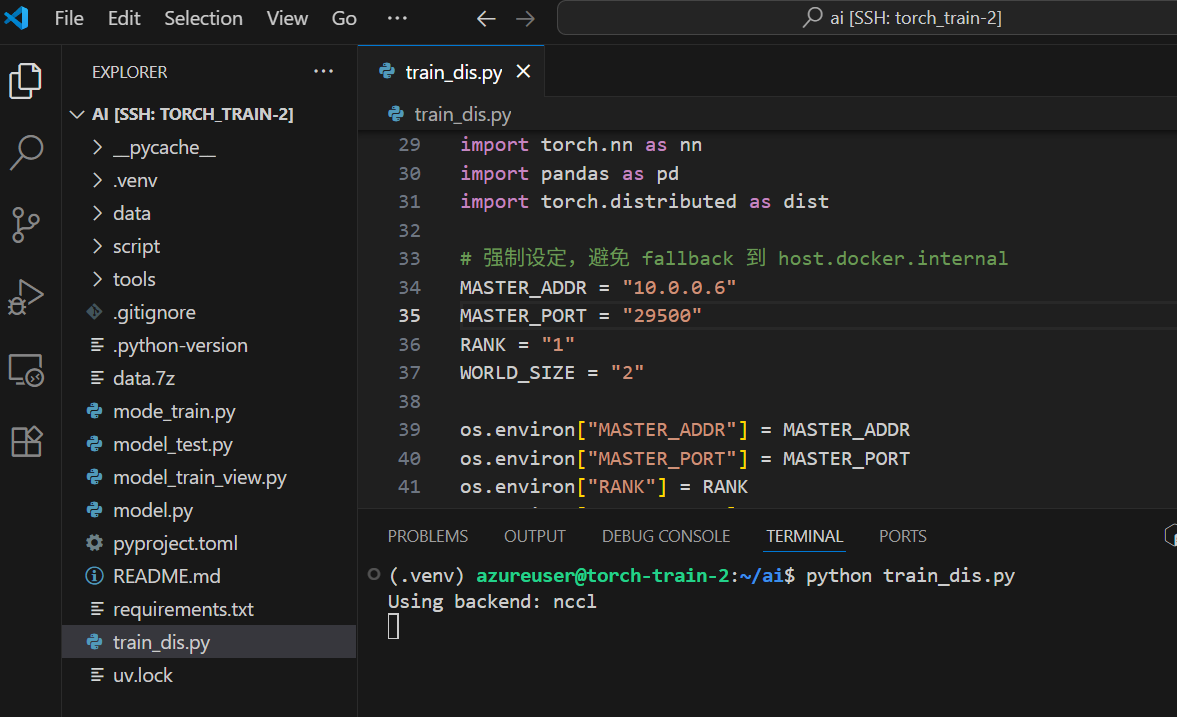
分布式训练的模式:# master 节点 $env:MASTER_ADDR="10.0.0.6" $env:MASTER_PORT="29505" $env:RANK="1" $env:WORLD_SIZE="2" python train_dis.py# worker 节点 $env:MASTER_ADDR="10.0.0.5" $env:MASTER_PORT="29500" $env:RANK="1" $env:WORLD_SIZE="2" python train_dis.py
使用场景为 多台机器,每台单张gpu
NCCL 与 GLOO
NCCL:
由 NVIDIA 开发,专为 GPU 间高效通信设计。
只支持 Linux 和 NVIDIA GPU。
性能高,适合大规模多卡/多机训练。
支持 AllReduce、Broadcast 等操作。
GLOO:
由 Facebook 开发,支持 CPU 和部分 GPU。
支持 Linux、Windows、macOS。
性能较 NCCL 低,适合 CPU 或小规模训练。
更通用,兼容性好。
torchrun 分布式训练
- torchrun 分布式训练的模式 【torchrun】
torchrun 只能在Linux机器上使用
- master
- node 1
- nvtop
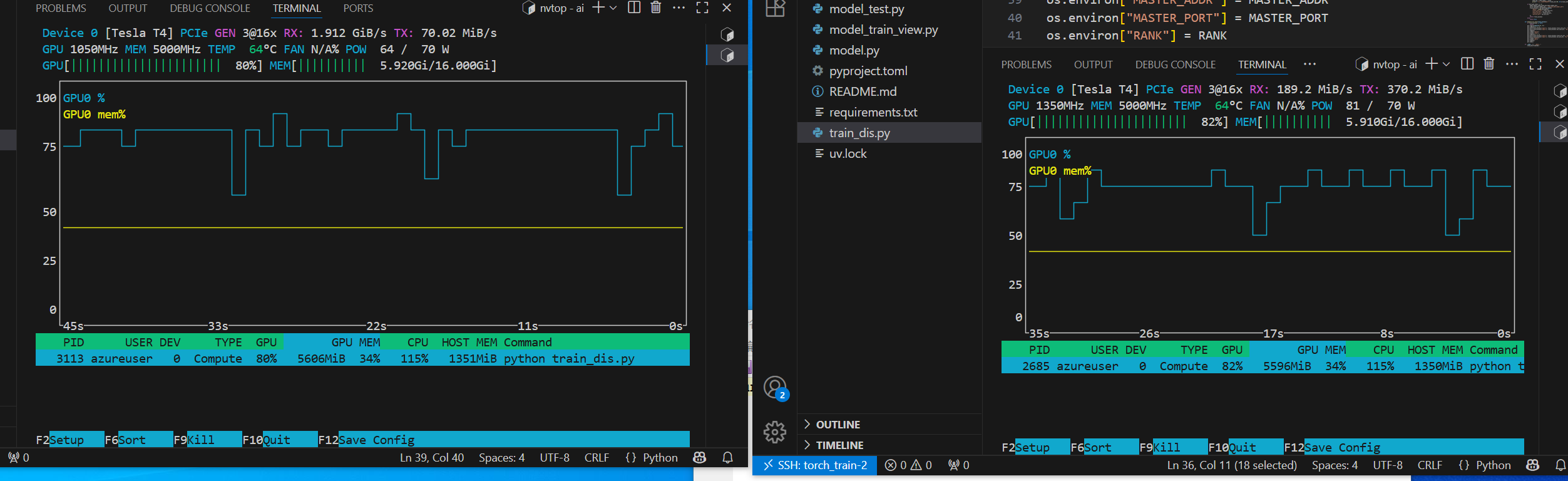
batchsize没微调,但速度很顶
实验总结与感悟
-
手动配置两台服务器很累,用脚本自动化解决会更简单
-
这只是简单的多机单卡模式,要是切换成多机多卡,要怎么维持?