需求
文档chunk操作和ocr以及语义识别太复杂了,手动实现太麻烦了,azure是有没有什么现成的服务来帮我一键搭建Rag服务,并给我一个对话功能?
有的有的, Azure AI Search 你值得拥有,这个Blog记录一下实验过程
项目架构
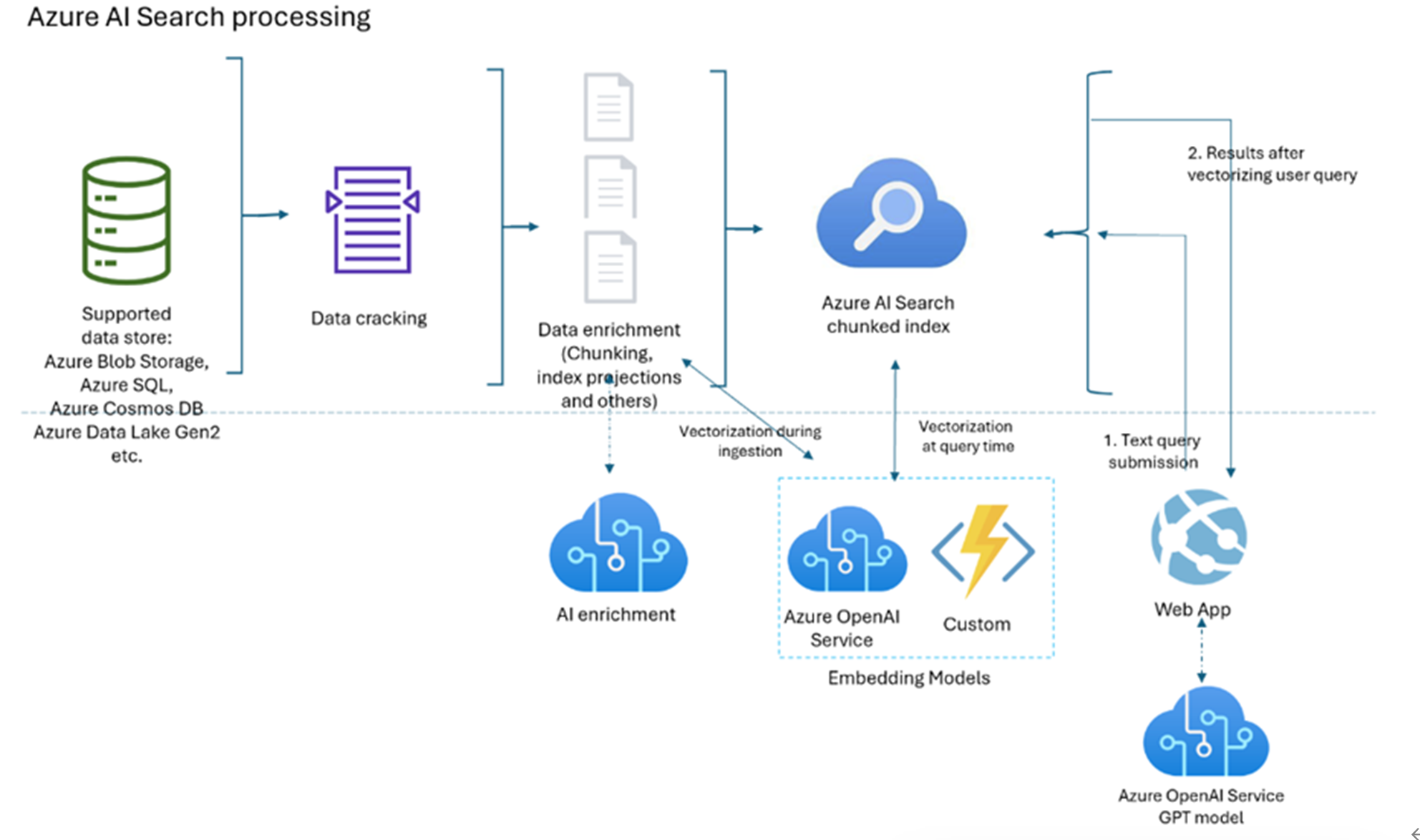
本项目全部组件均位于Azure云平台,涉及到了存储服务,AI Search 服务,AI Foundry 订阅服务,Azure OpenAI 服务
数据源层 (Supported data store)
数据源可以是来自 Azure Blob Storage, Azure SQL, Azure Cosmos DB, Azure Data Lake Gen2, etc的数据实例
数据破解(Data cracking)
- 功能:读取并解析各类格式(PDF、Office 文档、图片、数据库记录等),将其转成可处理的纯文本或结构化记录。
数据富集(Data enrichment)
Chunking(切片):将长文档拆成多个逻辑片段(chunk),以便后续索引和检索。
Index projections:生成片段级别的元数据投影,比如文本摘要、关键词、标签、实体识别结果等。
其他富集:OCR、语言检测、句法分析、图像标签提取等。
向量化注入(Vectorization during ingestion)
- Embedding Models:在数据入索引时,调用图中点虚线框里的服务——
- Azure OpenAI Service(官方 Embedding API)
- Custom Service(自定义模型,如 Sentence-BERT、Open-Source 模型等)
- 产出:为每个 chunk 生成固定长度的向量(embedding),并把它写入 Azure AI Search 的索引字段中。
Azure AI Search Chunked Index
- 索引结构:除了普通的文本倒排索引外,还包含“向量字段”,支持以向量形式进行相似度检索。
- 功能:统一管理所有切片及其向量,既可做传统关键词检索,也可做向量相似度检索。
RAG in Azure
RAG 原理介绍
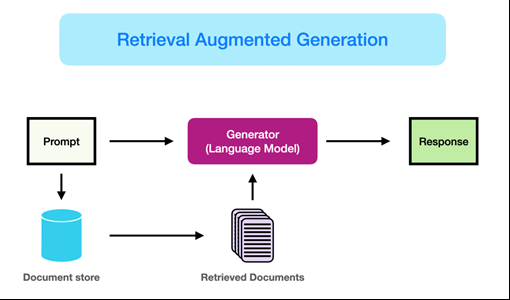
RAG(检索增强生成)技术为了解决纯生成模型记忆有限、时效性不足的问题,通过在生成前使用向量检索技术动态获取相关知识片段并将其注入到大规模语言模型的输入中,从而显著提升回答的准确性和可靠性。
RAG模型的工作流程可以分为两个主要阶段:检索阶段和生成阶段。
- 检索阶段
在检索阶段,RAG模型首先接收输入的查询(如用户提问),然后通过检索模块从预定义的知识库中查找与查询相关的文档或段落。这一步骤通常涉及到高效的向量搜索技术,如基于BERT的向量化方法,将文档和查询映射到相同的向量空间中,从而能够快速计算出文档与查询的相似度。检索模块会返回若干个与查询最相关的文档,这些文档将作为生成阶段的输入。
- 生成阶段
在生成阶段,RAG模型将检索到的文档和原始查询一起输入到生成模块中。生成模块通常是一个强大的生成模型,如T5或BART,它将利用检索到的文档信息生成最终的回答或文本。在这一过程中,生成模块能够参考检索到的背景信息,从而生成内容更加丰富、信息更加准确的回答。
Azure AI Search 介绍
**Azure AI Search(原名 Azure Cognitive Search)**是一项面向异构内容的企业级信息检索服务,支持对文档、数据库记录、图片等多种数据源进行统一索引,并通过 REST API 或 SDK 向应用和用户提供查询与检索功能。
· 核心架构与索引流程
-
数据获取与索引器(Indexer):通过内置的“拉取”式索引器定期从 Azure Blob、Azure SQL、Cosmos DB 等源头抓取数据,并根据字段映射将内容推送到搜索索引中。
-
认知技能管道(Skillset & AI Enrichment):在入索引前可接入 OCR、语言检测、实体提取等 AI 技能,将非结构化内容富集为结构化字段,提升后续检索与排序精度。
-
多重索引引擎:
-
- 倒排索引:传统关键词检索引擎,支持模糊匹配、短语检索、语言分析器等;
- 向量索引:在切片(chunk)级别对文本或图像片段做高维向量存储,支持基于余弦相似度或内积的近似最近邻检索(ANN)
· 在线查询与语义排名
- 查询处理:客户端提交自然语言或结构化查询,Azure AI Search 会将其解析为查询向量(用于向量检索)和查询条件(用于倒排索引检索),并行执行两种检索。
- 语义与自定义排序:检索到的候选结果可通过内置的语义排名器(Semantic Ranker)进一步优化,结合 BM25、向量相似度、打分脚本(Scoring Profiles)等多维度得分,返回最相关的结果。
- 生成式集成(RAG 场景):在检索增强生成应用中,可将返回的文档片段连同用户问题一起送入大型语言模型(LLM),实现基于上下文的生成式问答
一句话概括就是 AI Search 不光支持 向量检索还支持传统的 关键词 ,混合检索多种模式
Azure AI Foundry 介绍
**Azure AI Foundry(原 Azure AI Studio)**为团队提供了从“探索模型”到“部署应用Agent”的完整生命周期管理能力,包括可视化门户、统一 SDK 和丰富的 API,使开发者能够在企业级生产环境中快速构建、测试和运维 AI 解决方案。
-
核心组件
-
- 模型目录(Model Catalog):整合了来自 Microsoft、Azure OpenAI、DeepSeek、Hugging Face、Meta、Mistral 等多家厂商的预训练模型,支持在线评估和对比。
- Agent 框架(Agent Framework):提供预置模板与可插拔动作(Actions)及连接器(Connectors),快速构建知识驱动或流程自动化的智能 Agent。
- 低代码解决方案模式(Solution Patterns):内置多种行业和场景的示例架构,帮助用户无需从零开始即可“超级加速”AI 应用落地。
-
模型与生态
-
- 平台已汇聚超 1,900+ 款前沿与开源模型,包括 Elon Musk 的 Grok 3、各类大语言模型(LLM)与多种视觉/语音模型。
- 用户可基于公开数据集或自有测试集对模型进行性能 benchmark,并一键对比、选择最适合业务需求的模型版本。
-
Agent Service
-
- Azure AI Foundry Agent Service 已全面发布,为超过 10,000 家企业(如 Heineken、Carvana、Fujitsu)提供从“数据接入”到“流程编排”再到“自动执行” 的全托管 Agent 平台。
- 支持与 1,400+ 数据源(包括 SharePoint、Microsoft Fabric 及第三方系统)对接,内置安全审核与治理功能,保障生产环境的可靠性与可审计性。
-
典型应用场景
-
- 智能客服:结合 Retrieval & Q&A、Agent 自动化流程,实现面向企业知识库的精准问答与工单闭环。
- 代码现代化:利用 Copilot 集成,在 IDE(如 VS、GitHub)中快速重构、生成或优化代码。
- 业务流程自动化:通过 Agent Framework,构建“触发–决策–执行” 的端到端自动化流水线,替代手工操作。
实验过程
1. 创建一个资源组
取名为 用户名-rag-test
2. 准备一个存储账号
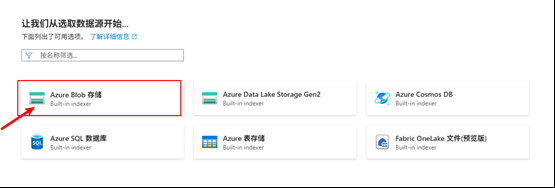
选择 Aure Blob存储 或 Azure Data Lake Storage Gen2
实验使用的其余选项全部默认即可.
2.1 创建一个 Blob 存储实例
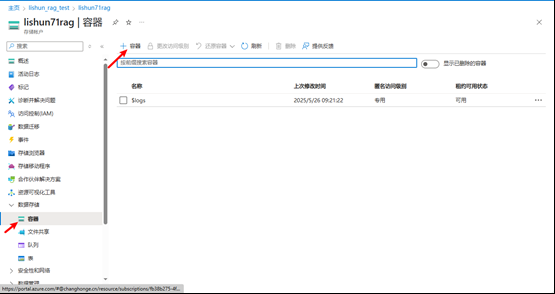
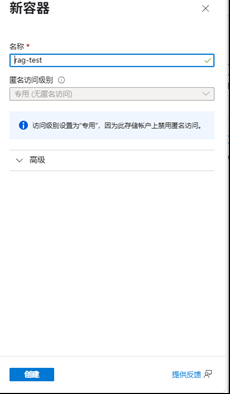
使用默认的配置即可,Blob名称容易即可.
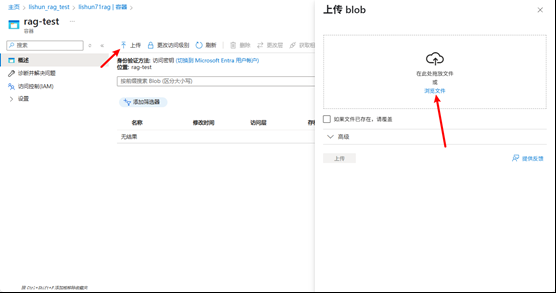
2.2 向Blob中上传一些文件
上传一些文档
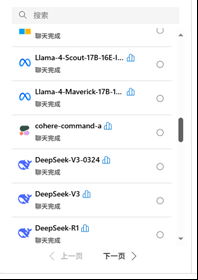
3. 创建 Azure AI Foundry / Azure OpenAI Foundry
注意: 是Azure AI Foundry,不是 Azure OpenAI Foundry
OpenAI Foundry 是专门调试 OpenAI Model 的平台.而 Azure AI Foundry 可以部署调试其他模型厂商的平台,比如Grok\DeepSeek\Llama等模型,并且支持调试 Agent,未来支持MCP\A2A\工作流等.
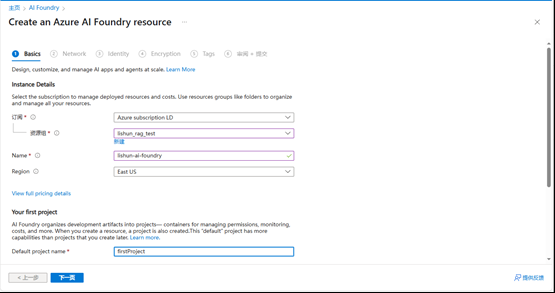
名称随意,地区选默认(East US)的即可,其余全部默认.
3.1 部署 chat 模型和 embedding 模型
- embedding model
截至2025年5月26日星期一为止,最新的 AI Search无法使用 AI Foundry中部署的 embedding模型,只能使用 OpenAI Foundry中的 embedding 模型
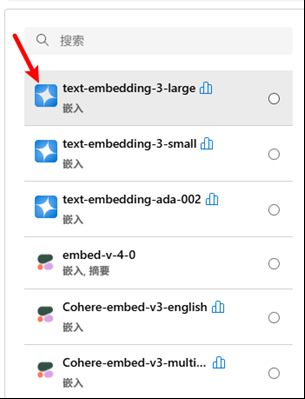
在 Azure OpenAI Foundry 中部署 embedding 模型
部署 text-embedding-3-large 嵌入模型做 embedding
- chat model
在 Azure AI Foundry 部署 chat 模型,
我们部署个 gpt-4o 即可
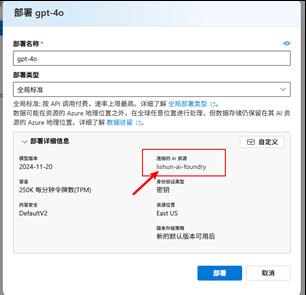
4. 创建 AI Search 服务
其余全部默认标准即可,推荐选择的位置和之前的项目保持一致.
4.1 创建Index/索引
我们现在有了Blob数据容器,里面的数据是非结构化的,我们做RAG,要将数据从文字----> Vector,存储结构的索引要变成Vector.
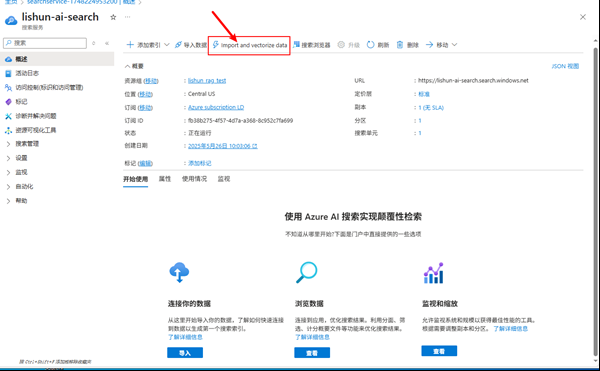
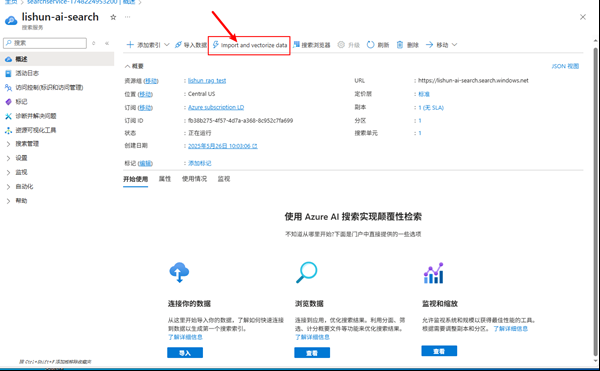
选择 import and vectorize data
4.2 普通 RAG / 多模式 RAG
我们现在有了Blob数据容器,里面的数据是非结构化的,我们做RAG,要将数据从文字----> Vector,存储结构的索引要变成Vector.
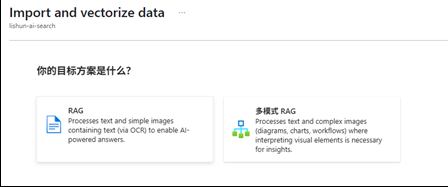
- 普通RAG
普通RAG 只能处理文本,如果有图片,是没法解决的;其中矢量化并扩充图像就是OCR部分
本次实验我们只做传统RAG,多模式的RAG后面再做.
选择之前创建的存储账户和Blob容器,
我们计划索引改成5分钟一次,这样可以做到增量更新,这一块Azure有增量创建索引的方案,后面再介绍.
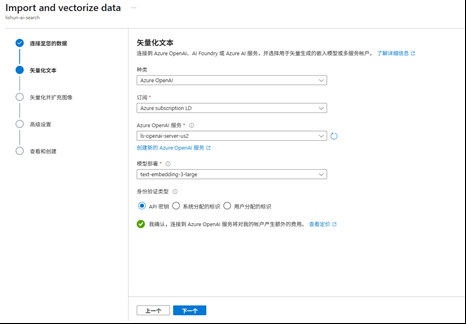
不进行矢量化图片的操作,如果对图片内容解析也有需求也可以选择。
- 多模式RAG
多模式的RAG,携带了图片语义识别,多模态大模型的嵌入
图片语义识别,就是用多模态大模型生成一段对图片描述性的文本内容
需要额外的多模态模型支持,比如 **gpt-4o **来对图片进行描述
4.3 测试
跳转到 AI Search 中进行检测
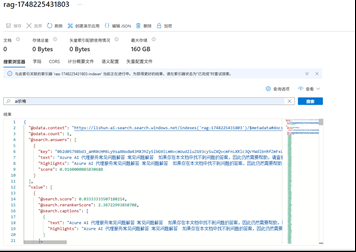
返回相似度和向量就说明成功了
5. RAG Agent 代理
创建 RAG Agent 来代理使用,外挂知识库
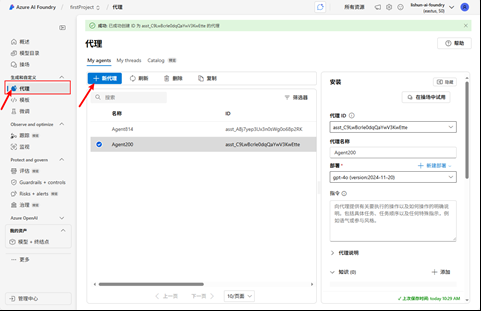
- 外挂知识库
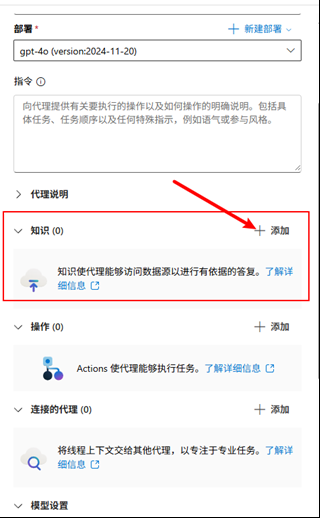
添加 Azure AI Serach 知识
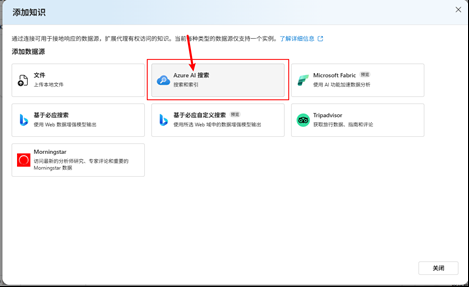
给这个知识一个名称,自己记住就行了,选择混合+语义即可
完全体大概这样
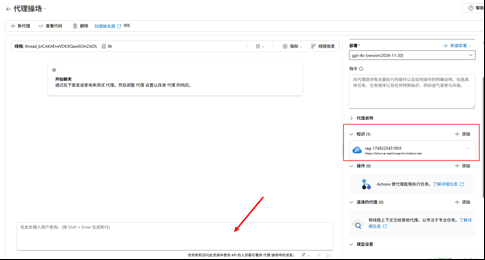
- 测试
问答即可,会返回本地知识库的知识
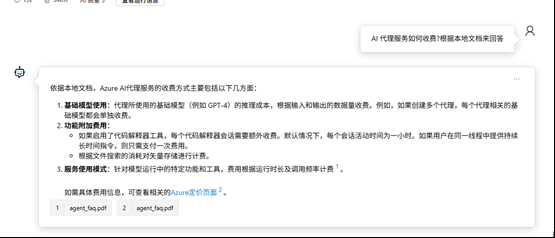
总结
-
Azure AI Search 价格不菲,弄完的实验忘了销毁给我一个月干了2k刀被骂惨了
-
Azure AI Search 可以独立使用,可以二次开发,当成多种信息检索的一种方式也是很不错的。
本文章图片很模糊的主要原因是为了一些保密处理,当时实验记录的图片比较仓促,凑合看吧,源文档就不发了