需求
部门内部需要一个内部的RAG系统,将AI结合提高工作效率,让我去找解决方案
要求有: 1.方便使用,2.可维护性和扩展性要高,3.效果要好,4.可以展示原文档
我当时想到的解决方案有:
- m365 copilot agent proxy【m365 copilot agent 代理】
好处:是微软产品,我们内部就有使用,还能无缝和m365产品绑定使用,坏处是没图片展示,访问具体文档还需要再点击,而且跳转访问的文件还存在问题
- dify
dify之前使用过,简单的纯文本文档没问题,但是需要OCR识别的文档或者LLM进行img2text就不行了,dify感觉还是只适合 workflow
- ragflow
开源,还支持本地部署的LLM以及embedding模型,还支持img2text,最最重要的是支持输出img和原文档。
回复的图片效果如下:
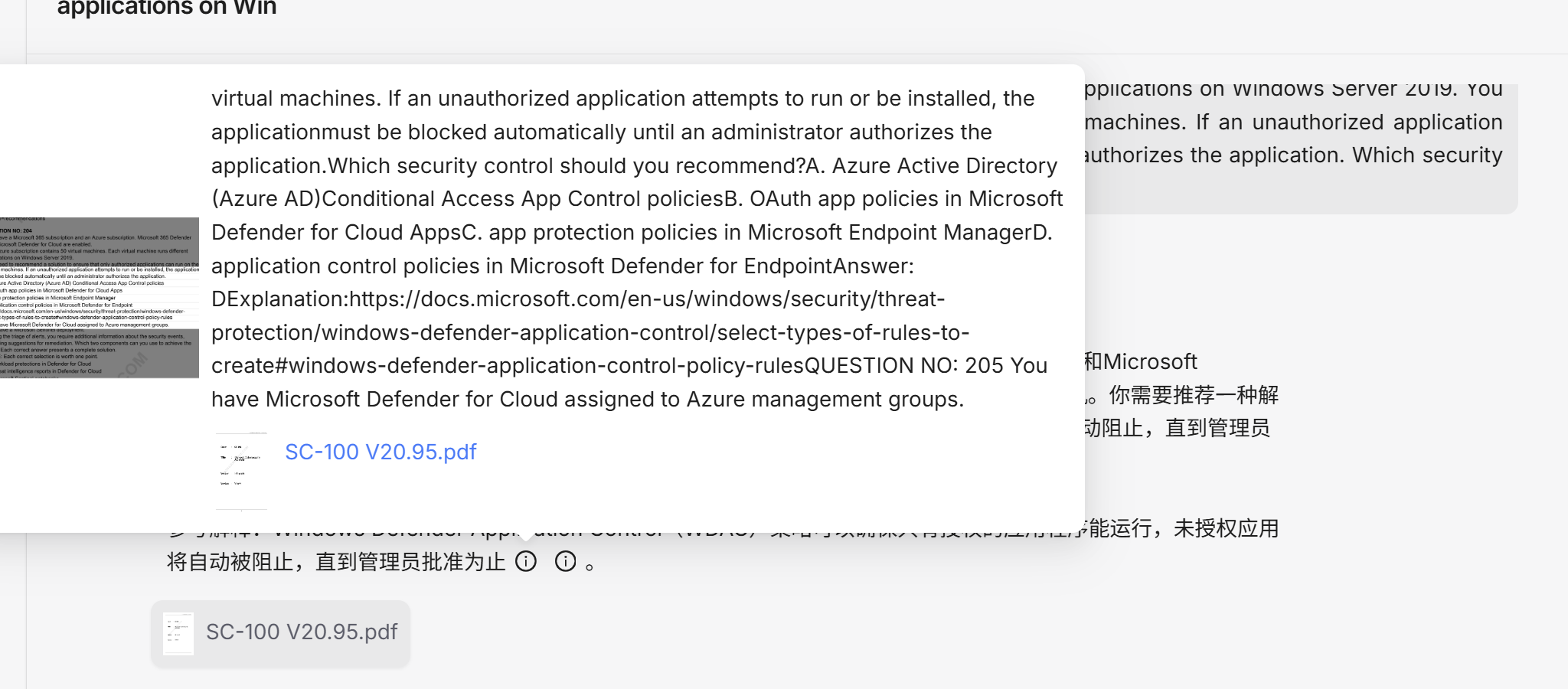
RagFlow效果还是很不错的,我还是比较满意的,就拟选定RagFlow来实现吧
RagFlow
docker compose 方式运行
修改上传文件的大小限制
文档类型处理
1. 纯文本文档
纯文本的.txt,.docx,.pdf,.md…
这类文档在RagFlow中直接使用 Naive Parser 模式就可以了,加速知识库的建立
- 功能:直接提取文本,不做 OCR 和复杂结构分析
- 优点:速度极快,非常适合纯文本 PDF / Word / TXT
- 缺点:不适合扫描件、含表格/复杂排版的文档
2. 文档 + 语义图片 + OCR部分
有些文档中夹杂着图片,这种图片没有文字,需要LLM进行语义理解,夹杂着一些扫描的文档
需要OCR + LLM
这类文档需要使用 DeepDoc Parser(默认) 模式。
- 功能:OCR(光学字符识别)、表格结构识别(TSR)、版面分析(DLA)
- 优点:适合扫描 PDF、复杂排版(多栏、表格、公式)
- 缺点:速度慢、资源占用高
3. 纯扫描的文档
扫描的文档内容,只需要OCR即可
使用的模式为 Image Parser(OCR 专用)
- 功能:针对图片(jpg/png)文档,直接 OCR 提取文字
- 优点:图像文档可用
- 缺点:识别效果依赖 OCR 模型