看到一个漫画网站,刚好里面有我想看的漫画,发现这个漫画网站对手机端极不友好,设置了自动跳转,广告数量过于恶心,所以决定写个脚本来爬取吧
初次尝试
- 网站地址
https://www.pipimanhua.com
初步写的代码
import requests
from lxml import etree
import os
import aiohttp
import asyncio
import aiofiles
import json
import async_timeout
import threading
import concurrent.futures
header = {
"User-Agent": ""
}
HEADER_URL = "https://www.pipimanhua.com"
# index_url = "https://www.pipimanhua.com/manhua/16624/"
index_url = "https://www.pipimanhua.com/manhua/13042/"
PAGE_URL_LIST = []
class Title:
def __init__(self, title, url):
self.title = title
self.url = url
# 1. 测试有没有 拦截
def get_index(url):
response = requests.get(url, headers=header)
if response.status_code == 200:
return response.text
return None
# 2. 获取每一章节的url信息
def get_echo_page_url(url,output_name):
response = requests.get(url, headers=header)
if response.status_code == 200:
html = etree.HTML(response.text)
li_list = html.xpath("/html/body/div[2]/section/div[3]/div/ul/li")
print(len(li_list))
for li in li_list:
# 获取li下a标签的href和文本
a = li.xpath("./a")[0]
href = HEADER_URL + a.xpath("./@href")[0]
text = a.xpath("./text()")[0]
# print(href, text)
PAGE_URL_LIST.append(Title(text, href))
# 检验
for title in PAGE_URL_LIST:
print(title.title, title.url)
with open(f"{output_name}.json", "w", encoding="utf-8") as f:
json.dump(
[{"title": t.title, "url": t.url} for t in PAGE_URL_LIST],
f,
ensure_ascii=False,
indent=4
)
return None
# 3. 获取每一页的具体内容
def get_page_img(title: Title):
imgs_list = []
response = requests.get(title.url, headers=header)
if response.status_code == 200:
html = etree.HTML(response.text)
img_list = html.xpath("//*[@id='article']//img[@data-original]")
for img in img_list:
src = img.xpath("./@data-original")[0]
print(src)
imgs_list.append(src)
os.makedirs(title.title, exist_ok=True)
for img in imgs_list:
requests.get(img, headers=header)
with open(os.path.join(title.title, img.split("/")[-1]), "wb") as f:
f.write(requests.get(img, headers=header).content)
return imgs_list
# 3.1 线程池加速
def download_img_thread(img, folder):
try:
response = requests.get(img, headers=header)
if response.status_code == 200:
filename = os.path.join(folder, img.split("/")[-1])
with open(filename, "wb") as f:
f.write(response.content)
except Exception as e:
print(f"Failed to download {img}: {e}")
def get_page_img_threed(title: Title):
imgs_list = []
response = requests.get(title.url, headers=header)
if response.status_code == 200:
html = etree.HTML(response.text)
img_list = html.xpath("//*[@id='article']//img[@data-original]")
for img in img_list:
src = img.xpath("./@data-original")[0]
print(src)
imgs_list.append(src)
os.makedirs(title.title, exist_ok=True)
with concurrent.futures.ThreadPoolExecutor(max_workers=8) as executor:
futures = [executor.submit(download_img_thread, img, title.title) for img in imgs_list]
concurrent.futures.wait(futures)
return imgs_list
# 3.2 异步 io 加速
async def download_img(session, img_url, folder, retries=3):
filename = os.path.join(folder, img_url.split("/")[-1])
for attempt in range(retries):
try:
async with async_timeout.timeout(30):
async with session.get(img_url, headers=header) as resp:
if resp.status == 200:
async with aiofiles.open(filename, "wb") as f:
content = await resp.read()
await f.write(content)
return
except Exception as e:
if attempt == retries - 1:
print(f"Failed to download {img_url}: {e}")
await asyncio.sleep(2)
async def get_page_img_async(title: Title):
imgs_list = []
async with aiohttp.ClientSession() as session:
async with session.get(title.url, headers=header) as response:
if response.status == 200:
text = await response.text()
html = etree.HTML(text)
img_list = html.xpath("//*[@id='article']//img[@data-original]")
for img in img_list:
src = img.xpath("./@data-original")[0]
print(src)
imgs_list.append(src)
os.makedirs(title.title, exist_ok=True)
tasks = [download_img(session, img, title.title) for img in imgs_list]
await asyncio.gather(*tasks)
return imgs_list
async def batch_download_titles(title_list, limit=5):
sem = asyncio.Semaphore(limit)
async def sem_task(title):
async with sem:
await get_page_img_async(title)
tasks = [sem_task(title) for title in title_list]
await asyncio.gather(*tasks)
# 测试能不能连接成功
# print(get_index(index_url))
get_echo_page_url(index_url,"斗破苍穹")
def main():
with open("test.json", "r", encoding="utf-8") as f:
PAGE_URL_LIST = json.load(f)
titles = [Title(t["title"], t["url"]) for t in PAGE_URL_LIST]
for title in titles:
get_page_img_threed(title)
上述的做法有一些问题,异步IO速度太快会被封,所以最后选择了线程池
但是后面发现这个 网站的部分章节存在页面加密情况 ------> JS混淆 大约为 1/5 的部分
由于我对 JS反混淆能力太差了,而目标网站是一个 PHP 纯静态,最多一点动态变化的网站,
我决定直接使用 playwright 来直接获取执行完 js 的页面
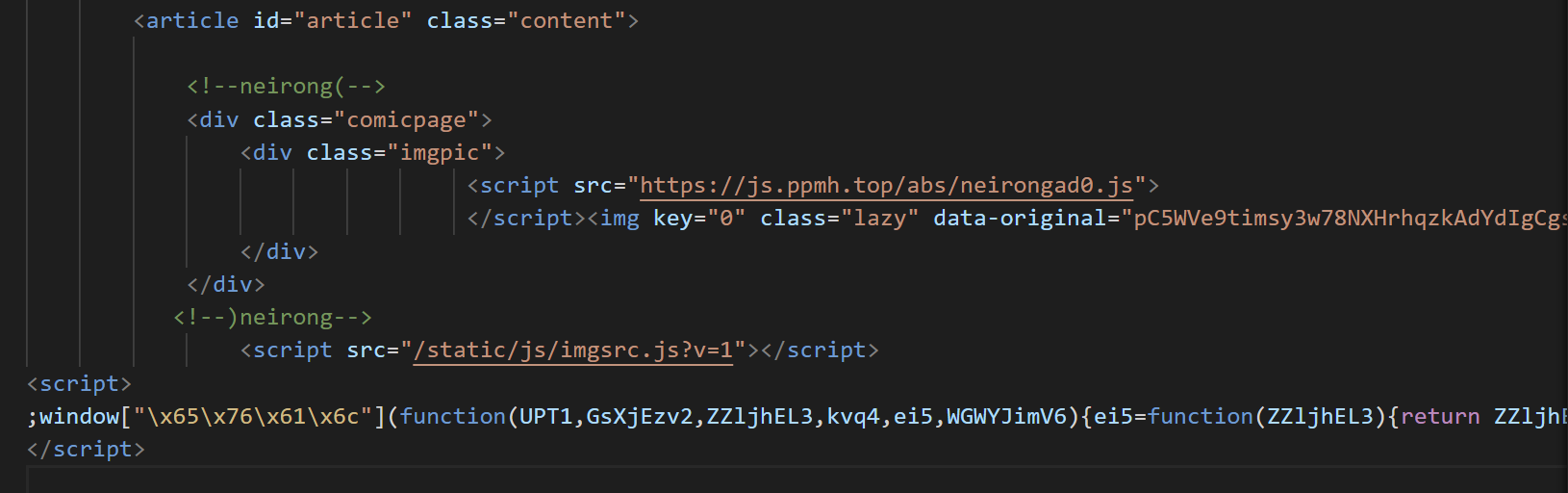
比如这个页面,实在 反混淆能力比较差,直接放弃了,有兴趣的自己来试试
https://www.pipimanhua.com/read/16574/932920.html
换一个思路
我重新理了一下思路,我应该在爬取的时候使用低频率解析出取所有的 图片url
再单独写具体爬取的脚本
数据一:
- 章节名和url
[
{
"title": "01",
"url": "https://www.pipimanhua.com/read/13042/745262.html"
},
{
"title": "02",
"url": "https://www.pipimanhua.com/read/13042/745263.html"
},
...
]
使用的脚本为:
import requests
from lxml import etree
import os
import aiohttp
import asyncio
import aiofiles
import json
import async_timeout
import threading
import concurrent.futures
header = {
"User-Agent": ""
}
HEADER_URL = "https://www.pipimanhua.com"
# index_url = "https://www.pipimanhua.com/manhua/16624/"
index_url = "https://www.pipimanhua.com/manhua/13042/"
PAGE_URL_LIST = []
class Title:
def __init__(self, title, url):
self.title = title
self.url = url
# 1. 测试有没有 拦截
def get_index(url):
response = requests.get(url, headers=header)
if response.status_code == 200:
return response.text
return None
# 2. 获取每一章节的url信息
def get_echo_page_url(url,output_name):
response = requests.get(url, headers=header)
if response.status_code == 200:
html = etree.HTML(response.text)
li_list = html.xpath("/html/body/div[2]/section/div[3]/div/ul/li")
print(len(li_list))
for li in li_list:
# 获取li下a标签的href和文本
a = li.xpath("./a")[0]
href = HEADER_URL + a.xpath("./@href")[0]
text = a.xpath("./text()")[0]
# print(href, text)
PAGE_URL_LIST.append(Title(text, href))
# 检验
for title in PAGE_URL_LIST:
print(title.title, title.url)
with open(f"{output_name}.json", "w", encoding="utf-8") as f:
json.dump(
[{"title": t.title, "url": t.url} for t in PAGE_URL_LIST],
f,
ensure_ascii=False,
indent=4
)
return None
# 测试能不能连接成功
# print(get_index(index_url))
get_echo_page_url(index_url,"斗破苍穹")
数据二:
- 章节名与各图片url
[
{
"title": "004 喧锣镇技能商店",
"images": [
"https://res2.tupian.run/res1_gf/0851571ea6/48755/0_vx.webp",
"https://res2.tupian.run/res1_gf/0851571ea6/48755/1_j1.webp",
"https://res2.tupian.run/res1_gf/0851571ea6/48755/2_x7.webp",
"https://res2.tupian.run/res1_gf/0851571ea6/48755/3_qq.webp",
"https://res2.tupian.run/res1_gf/0851571ea6/48755/4_0u.webp",
"https://res2.tupian.run/res1_gf/0851571ea6/48755/5_al.webp",
"https://res2.tupian.run/res1_gf/0851571ea6/48755/6_u6.webp",
"https://res2.tupian.run/res1_gf/0851571ea6/48755/7_7b.webp",
"https://res2.tupian.run/res1_gf/0851571ea6/48755/8_5u.webp",
"https://res2.tupian.run/res1_gf/0851571ea6/48755/9_mw.webp",
"https://res2.tupian.run/res1_gf/0851571ea6/48755/10_ma.webp",
"https://res2.tupian.run/res1_gf/0851571ea6/48755/11_76.webp",
"https://res2.tupian.run/res1_gf/0851571ea6/48755/12_80.webp",
"https://res2.tupian.run/res1_gf/0851571ea6/48755/13_bb.webp",
"https://res2.tupian.run/res1_gf/0851571ea6/48755/14_le.webp",
"https://res2.tupian.run/res1_gf/0851571ea6/48755/15_j3.webp",
"https://res2.tupian.run/res1_gf/0851571ea6/48755/16_gb.webp",
"https://res2.tupian.run/res1_gf/0851571ea6/48755/17_aw.webp",
"https://res2.tupian.run/res1_gf/0851571ea6/48755/18_1y.webp",
"https://res2.tupian.run/res1_gf/0851571ea6/48755/19_5l.webp",
"https://res2.tupian.run/res1_gf/0851571ea6/48755/20_5m.webp",
"https://res2.tupian.run/res1_gf/0851571ea6/48755/21_y1.webp",
"https://res2.tupian.run/res1_gf/0851571ea6/48755/22_xe.webp",
"https://res2.tupian.run/res1_gf/0851571ea6/48755/23_u8.webp",
"https://res2.tupian.run/res1_gf/0851571ea6/48755/24_l5.webp",
"https://res2.tupian.run/res1_gf/0851571ea6/48755/25_gz.webp",
"https://res2.tupian.run/res1_gf/0851571ea6/48755/26_8e.webp"
]
},
...
]
import os
import asyncio
import json
from playwright.async_api import async_playwright
BASE_DIR = "鲲吞天下"
class Title:
def __init__(self, title, url):
self.title = title
self.url = url
async def get_page_img_playwright(page, title: Title):
imgs_list = []
try:
await page.goto(title.url, timeout=120000, wait_until="domcontentloaded")
await page.wait_for_selector("#article")
img_elements = await page.query_selector_all("#article img[data-original]")
for img in img_elements:
src = await img.get_attribute("data-original")
if src:
imgs_list.append(src)
except Exception as e:
print(f"Error: {title.title} - {e}")
return imgs_list,title
async def worker(queue, results):
async with async_playwright() as p:
browser = await p.chromium.launch(headless=True)
pages = [await browser.new_page() for _ in range(10)]
while not queue.empty():
tasks = []
for page in pages:
if queue.empty():
break
title = await queue.get()
tasks.append(asyncio.create_task(get_page_img_playwright(page, title)))
for i, task in enumerate(tasks):
imgs,title = await task
results.append({"title": title.title , "images": imgs})
print(f"{title.title} with {len(imgs)} ")
await browser.close()
async def main():
# 读取待解析对象
with open("鲲吞天下.json", "r", encoding="utf-8") as f:
PAGE_URL_LIST = json.load(f)
titles = [Title(t["title"], t["url"]) for t in PAGE_URL_LIST]
# 创建队列
queue = asyncio.Queue()
for t in titles:
await queue.put(t)
results = []
# 创建工作线程池
await worker(queue, results)
# 等待所有的任务完成
if queue.empty():
print("All tasks completed.")
# 写入
try:
results.sort(key=lambda x: x["title"])
with open("imgs_debug.json", "w", encoding="utf-8") as f:
json.dump(results, f, ensure_ascii=False, indent=4)
except Exception as e:
print(f"Error occurred while writing to file: {e}")
if __name__ == "__main__":
asyncio.run(main())
- 批量爬取数据
BOOK
Title1
img1
img2
...
Title2
img1
img2
...
...
import requests
import json
import os
import asyncio
import aiohttp
BASE_DIR = "鲲吞天下"
MAX_CONCURRENT = 50 # 最大并发数
JSON_FILE = "imgs_debug.json"
class ImageData:
def __init__(self, title, images):
self.title = title
self.images = images
IMAGE_LIST = []
with open(JSON_FILE, "r", encoding="utf-8") as f:
data = json.load(f)
for item in data:
title = item["title"]
images = item["images"]
image_data = ImageData(title, images)
IMAGE_LIST.append(image_data)
def mkdir_page_dir(title):
os.makedirs(f"{BASE_DIR}/{title}", exist_ok=True)
return f"{BASE_DIR}/{title}"
async def get_imgs_from_url(semaphore, folder_path, file_name, image_url):
async with semaphore:
try:
async with aiohttp.ClientSession() as session:
async with session.get(image_url) as response:
with open(f"{folder_path}/{file_name}", "wb") as out_file:
out_file.write(await response.read())
except Exception as e:
print(f"Failed to download {image_url}: {e}")
print(image_data.title, image_url)
async def main():
semaphore = asyncio.Semaphore(MAX_CONCURRENT)
tasks = []
for image_data in IMAGE_LIST:
folder_path = mkdir_page_dir(image_data.title)
for image_url in image_data.images:
file_name = image_url.split("/")[-1]
tasks.append(get_imgs_from_url(semaphore, folder_path, file_name, image_url))
await asyncio.gather(*tasks)
print("All images downloaded successfully.")
if __name__ == "__main__":
asyncio.run(main())
在手机上爽看
- Perfect Viewer

将所有文件打包,放手机里用这个软件来看,既可以避免 动漫图片出现在手机相册,又能爽看无需解压
看本子利器
- 效果还是不错的
