需求
印度英语翻译成中文,如果可以进一步需要实现一个实时推理或者伪实时推理
本blog记录一下自己跑这些模型的感受
参考音频,下载连接如下:
https://lishun-cdn-e9djhre3gbe6ftd8.z01.azurefd.net/imgs/audio1_ids.wav
CDN下载
参考文章
HuggingFaceASR榜单
Open ASR Leaderboard - a Hugging Face Space by hf-audio
技术选型
| 模型 | 支持任务 | 参数大小 | 推理速度 (RTFx) | 平均准确率(WER) | 社区情况 |
|---|---|---|---|---|---|
| Whisper | ASR/S2TT【en】 | 39M–1.55B | 145.51 | 7.44% | 十分活跃 |
| Seamless (SeamlessStreaming) | ASR/S2TT/S2ST | 未公开 | 未公开 | 未公开 | 活跃 |
| Phi-4-multimodal-instruct | ASR/S2TT/LLM | 5.6B | 62.12 | 6.14 | 活跃 |
| Canary-Qwen-2.5B | ASR/LLM | 2.5B | 418 | 5.63% | 活跃 |
| Canary-1b-v2 | ASR | 1B | 749 | 7.15% | 活跃 |
| Parakeet-TDT-0.6B-v2 | ASR | 600M | 418.28 | 9.87% | 活跃 |
各个模型对比
1. Whisper系列
whisper模型是
2. Parakeet-TDT-0.6B-v2
GPU占用情况:
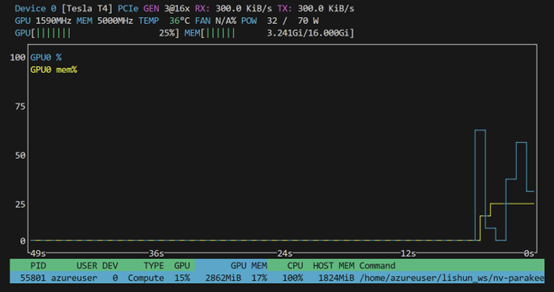
推理速度: 1分35秒的语音只花了 2.0357439517974854 s来推理!!
这个模型有黑科技,推理速度非常非常快,快准狠
参考情况
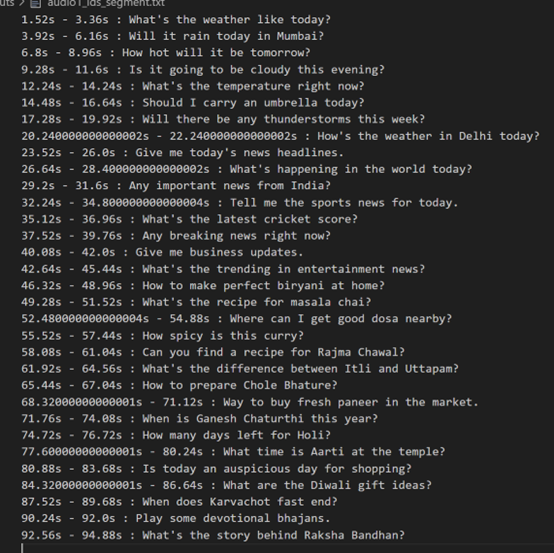
3. Phi-4-multimodal-instruct
GPU占用情况:
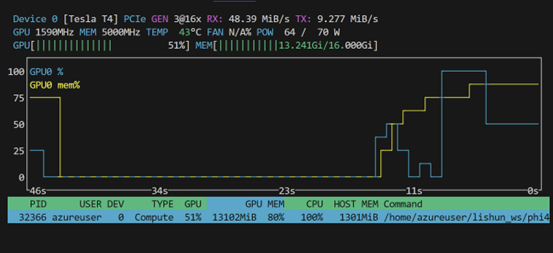
使用的代码为:
处理1分35秒音频,识别并翻译总耗时44.47725319862366 seconds
处理5秒的音频,识别并翻译总耗时3.388068914413452 seconds
语义的理解很好
4. Seamless (SeamlessStreaming)
5. Canary系列
结论
纯英文使用 Parakeet-TDT-0.6B-v2,又快又准
小语种用 whisper ,方便微调和训练
要用大模型就 Phi-4multimodal-instruct