根据官方demo快速上手
trt-llm 来加速大模型的推理
目前常用的加速方案有: vllm,ollama,tensorRT-LLM
tensorRT-LLM
Installing on Linux via pip — TensorRT-LLM
中文文档:
环境搭建
py环境
本地使用的是 Tesla T4显卡 / A100 显卡
使用 Tesla T4 的时候会出现一些问题,由于Tesla T4显卡的版本太老,会导致无法使用一些新版本的功能,导致 core dump。
所以后续的实验都是在 A100 机器上进行的。
使用 python 3.10 / python3.12 的版本
# Optional step: Only required for NVIDIA Blackwell GPUs and SBSA platform
uv pip install torch==2.7.1 torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128
sudo apt-get -y install libopenmpi-dev
uv pip install --upgrade pip setuptools
uv pip install --extra-index-url https://pypi.nvidia.com/ tensorrt-llm
原始的仓库为 pypi 但是最新的仓库放在 pypi.nvidia仓库下
出现了报错:
(.tensorRT-llm) (base) azureuser@torch-train-1:~/lishun_ws/nv-triton-inference-server/tensorRT-LLM$ python main.py
/home/azureuser/lishun_ws/nv-triton-inference-server/tensorRT-LLM/.tensorRT-llm/lib/python3.12/site-packages/torch/cuda/init.py:61: FutureWarning: The pynvml package is deprecated. Please install nvidia-ml-py instead. If you did not install pynvml directly, please report this to the maintainers of the package that installed pynvml for you.
import pynvml # type: ignore[import]
Traceback (most recent call last):
File “/home/azureuser/lishun_ws/nv-triton-inference-server/tensorRT-LLM/main.py”, line 1, in
from tensorrt_llm import LLM, SamplingParams
File “/home/azureuser/lishun_ws/nv-triton-inference-server/tensorRT-LLM/.tensorRT-llm/lib/python3.12/site-packages/tensorrt_llm/init.py”, line 36, in
import tensorrt_llm.functional as functional
File “/home/azureuser/lishun_ws/nv-triton-inference-server/tensorRT-LLM/.tensorRT-llm/lib/python3.12/site-packages/tensorrt_llm/functional.py”, line 29, in
from . import graph_rewriting as gw
File “/home/azureuser/lishun_ws/nv-triton-inference-server/tensorRT-LLM/.tensorRT-llm/lib/python3.12/site-packages/tensorrt_llm/graph_rewriting.py”, line 12, in
from .network import Network
File “/home/azureuser/lishun_ws/nv-triton-inference-server/tensorRT-LLM/.tensorRT-llm/lib/python3.12/site-packages/tensorrt_llm/network.py”, line 31, in
from tensorrt_llm.module import Module
File “/home/azureuser/lishun_ws/nv-triton-inference-server/tensorRT-LLM/.tensorRT-llm/lib/python3.12/site-packages/tensorrt_llm/module.py”, line 17, in
from ._common import default_net
File “/home/azureuser/lishun_ws/nv-triton-inference-server/tensorRT-LLM/.tensorRT-llm/lib/python3.12/site-packages/tensorrt_llm/_common.py”, line 40, in
from .plugin import _load_plugin_lib
File “/home/azureuser/lishun_ws/nv-triton-inference-server/tensorRT-LLM/.tensorRT-llm/lib/python3.12/site-packages/tensorrt_llm/plugin/init.py”, line 15, in
from .plugin import (TRT_LLM_PLUGIN_NAMESPACE, PluginConfig, _load_plugin_lib,
File “/home/azureuser/lishun_ws/nv-triton-inference-server/tensorRT-LLM/.tensorRT-llm/lib/python3.12/site-packages/tensorrt_llm/plugin/plugin.py”, line 28, in
from …_ipc_utils import IpcMemory, can_access_peer
File “/home/azureuser/lishun_ws/nv-triton-inference-server/tensorRT-LLM/.tensorRT-llm/lib/python3.12/site-packages/tensorrt_llm/_ipc_utils.py”, line 20, in
from cuda import cuda, cudart
ImportError: cannot import name ‘cuda’ from ‘cuda’ (unknown location)
解决方法
下载与cuda-toolkit版本对应的cuda-python
比如 本项目使用的是 cu128
则要下载 cuda-python==12.8
uv pip install cuda-python==12.8
环境一直搞不好,还是拉docker来解决吧,推理一直会报错,各种古怪问题
后续排查发现是自己的显卡太老了,已经tensorRT-LLM都支持我这个卡的推理了
推理demo
from tensorrt_llm import LLM, SamplingParams
def main():
# Model could accept HF model name, a path to local HF model,
# or TensorRT Model Optimizer's quantized checkpoints like nvidia/Llama-3.1-8B-Instruct-FP8 on HF.
llm = LLM(model="TinyLlama/TinyLlama-1.1B-Chat-v1.0")
# Sample prompts.
prompts = [
"Hello, my name is",
"The capital of France is",
"The future of AI is",
]
# Create a sampling params.
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
for output in llm.generate(prompts, sampling_params):
print(
f"Prompt: {output.prompt!r}, Generated text: {output.outputs[0].text!r}"
)
# Got output like
# Prompt: 'Hello, my name is', Generated text: '\n\nJane Smith. I am a student pursuing my degree in Computer Science at [university]. I enjoy learning new things, especially technology and programming'
# Prompt: 'The president of the United States is', Generated text: 'likely to nominate a new Supreme Court justice to fill the seat vacated by the death of Antonin Scalia. The Senate should vote to confirm the'
# Prompt: 'The capital of France is', Generated text: 'Paris.'
# Prompt: 'The future of AI is', Generated text: 'an exciting time for us. We are constantly researching, developing, and improving our platform to create the most advanced and efficient model available. We are'
if __name__ == '__main__':
main()
- 运行
由于显卡比较老,需要加参数避免 core dumpe,实际测试还是会 core dump
export TRTLLM_DISABLE_FMHA=1
export TORCH_CUDA_ARCH_LIST=7.5
python main.py
docker 环境
docker run --ipc host --gpus all -it nvcr.io/nvidia/tensorrt-llm/release
–ipc host:容器与主机共享 IPC(进程间通信)命名空间,适用于需要高效进程通信的深度学习任务。
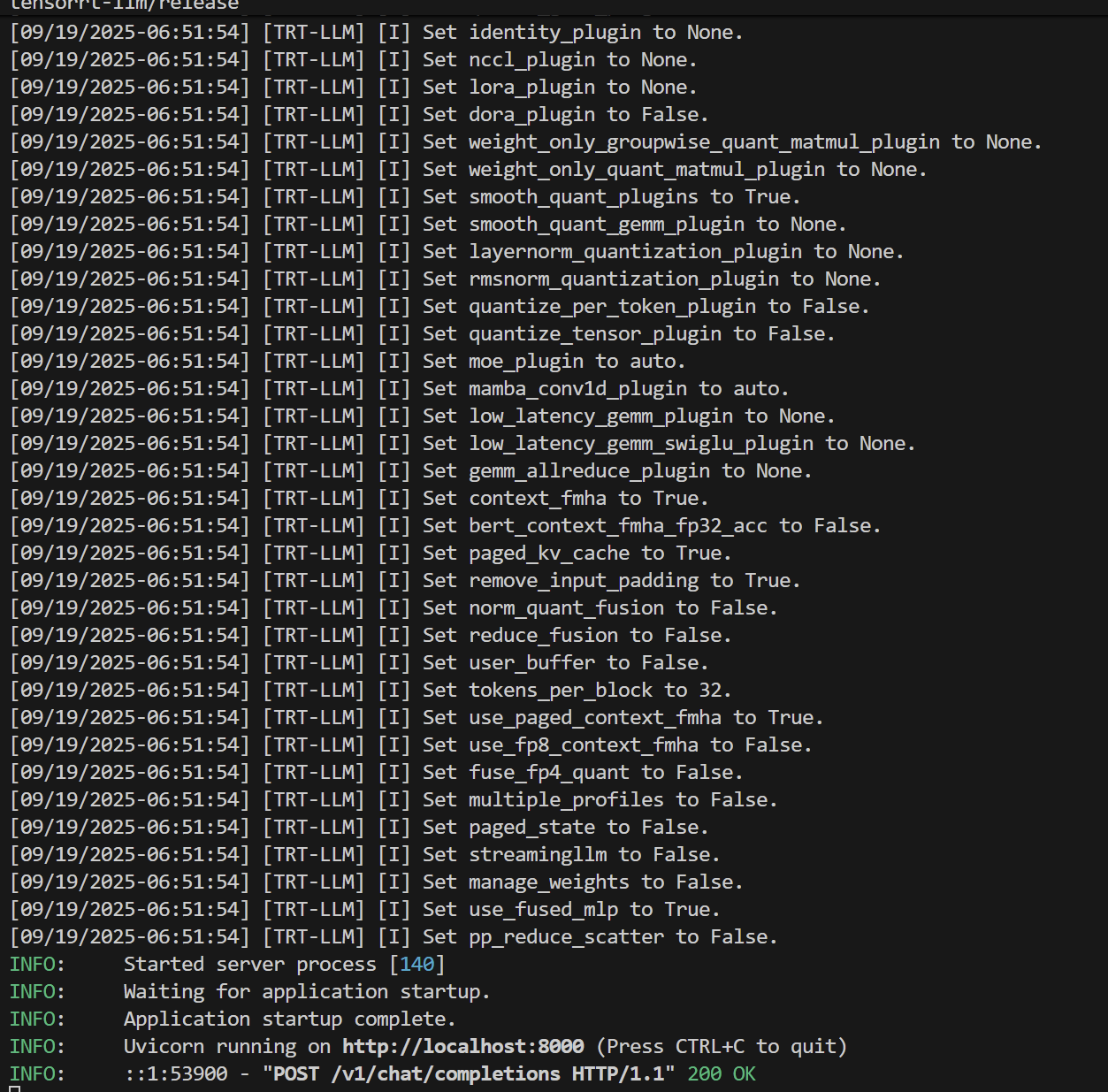
启动服务
trtllm-serve "TinyLlama/TinyLlama-1.1B-Chat-v1.0"
client端
curl -X POST http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Accept: application/json" \
-d '{
"model": "TinyLlama/TinyLlama-1.1B-Chat-v1.0",
"messages":[{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Where is New York? Tell me in a single sentence."}],
"max_tokens": 32,
"temperature": 0
}'
实例输出
{"id":"chatcmpl3317bfedef0f42fcb6bac75d05ef60e9",
"object":"chat.completion",
"created":1758265112,
"model":"TinyLlama/TinyLlama-1.1B-Chat-v1.0",
"choices":[
{"index":0,"message":
{"role":"assistant",
"content":"New York is a city in the northeastern United States, located on the eastern coast of the state of New York.",
"reasoning_content":null,
"tool_calls":[]
},
"logprobs":null,
"finish_reason":"stop",
"stop_reason":null,
"disaggregated_params":null
}
],
"usage":{"prompt_tokens":43,"total_tokens":69,"completion_tokens":26}
}
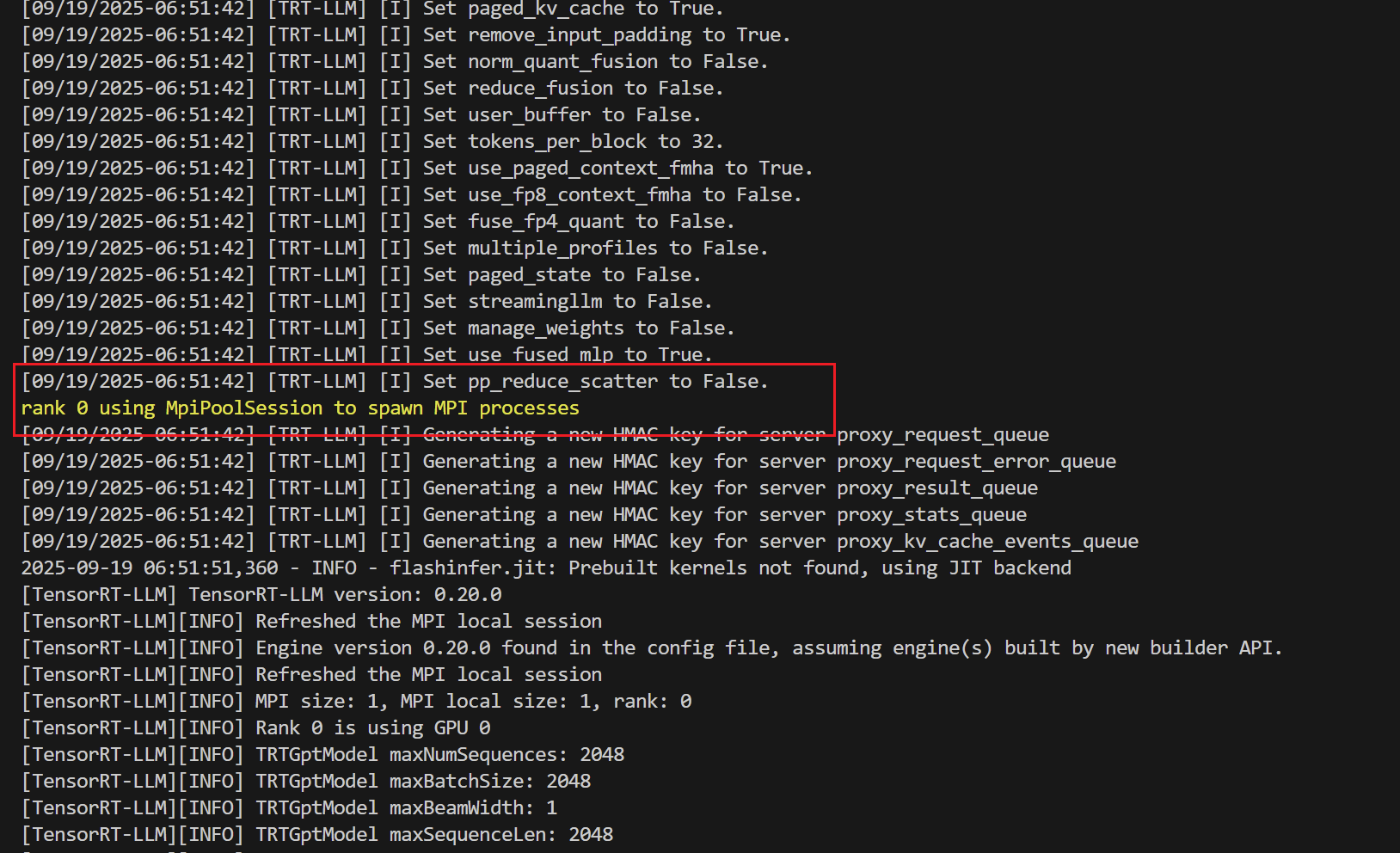
奇怪问题:
本地环境中使用这个命令会卡死在
rank 0 using MpiPoolSession to spawn MPI processes
但在docker环境下卡一下又好了
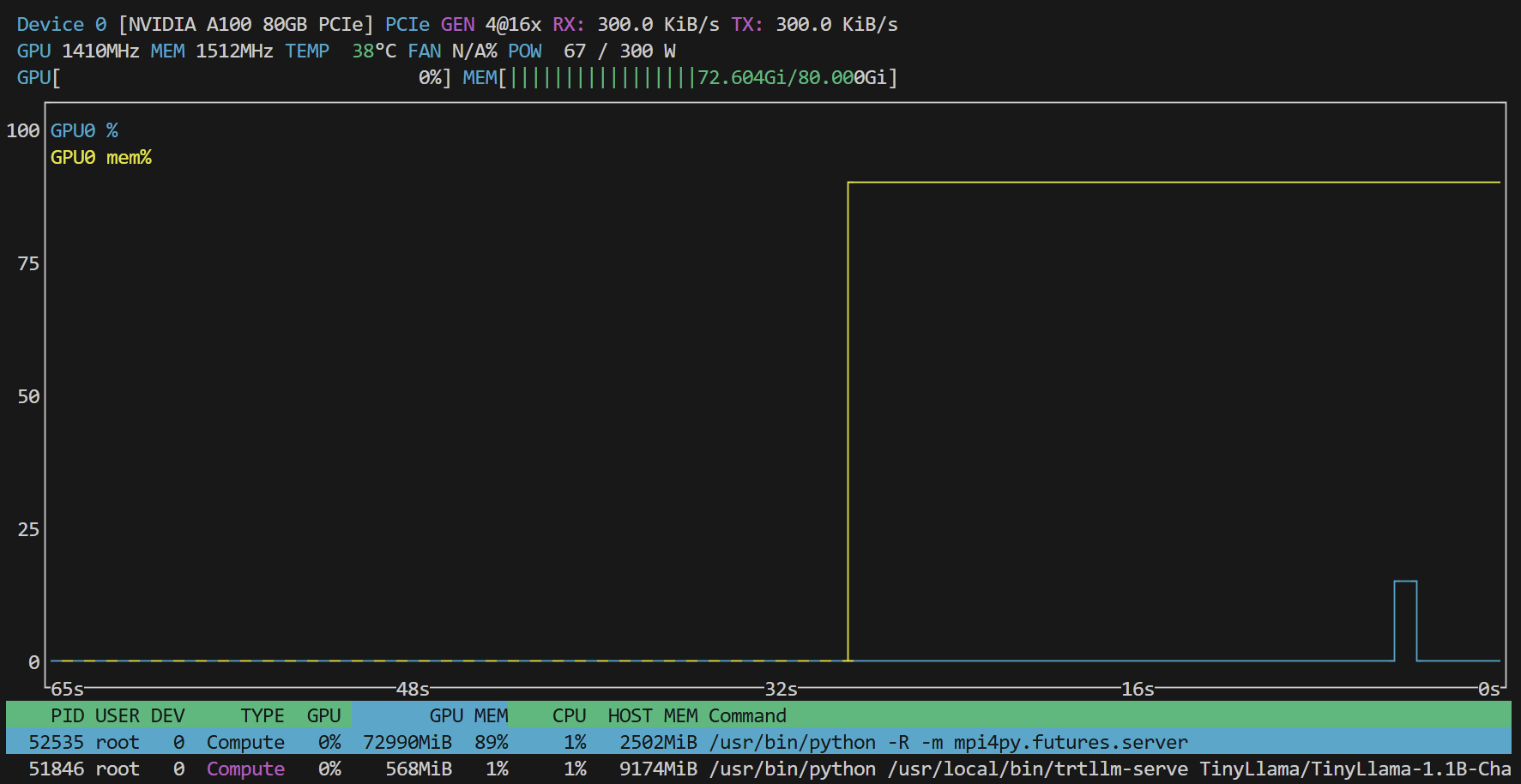
测试并发
- 采用 ApacheBench
echo '{
"model": "TinyLlama/TinyLlama-1.1B-Chat-v1.0",
"messages":[{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Where is New York? Tell me in a single sentence."}],
"max_tokens": 32,
"temperature": 0
}' > payload.json
ab -n 1000 -c 1000 -p payload.json -T "application/json" http://localhost:8000/v1/chat/completions
数据水平
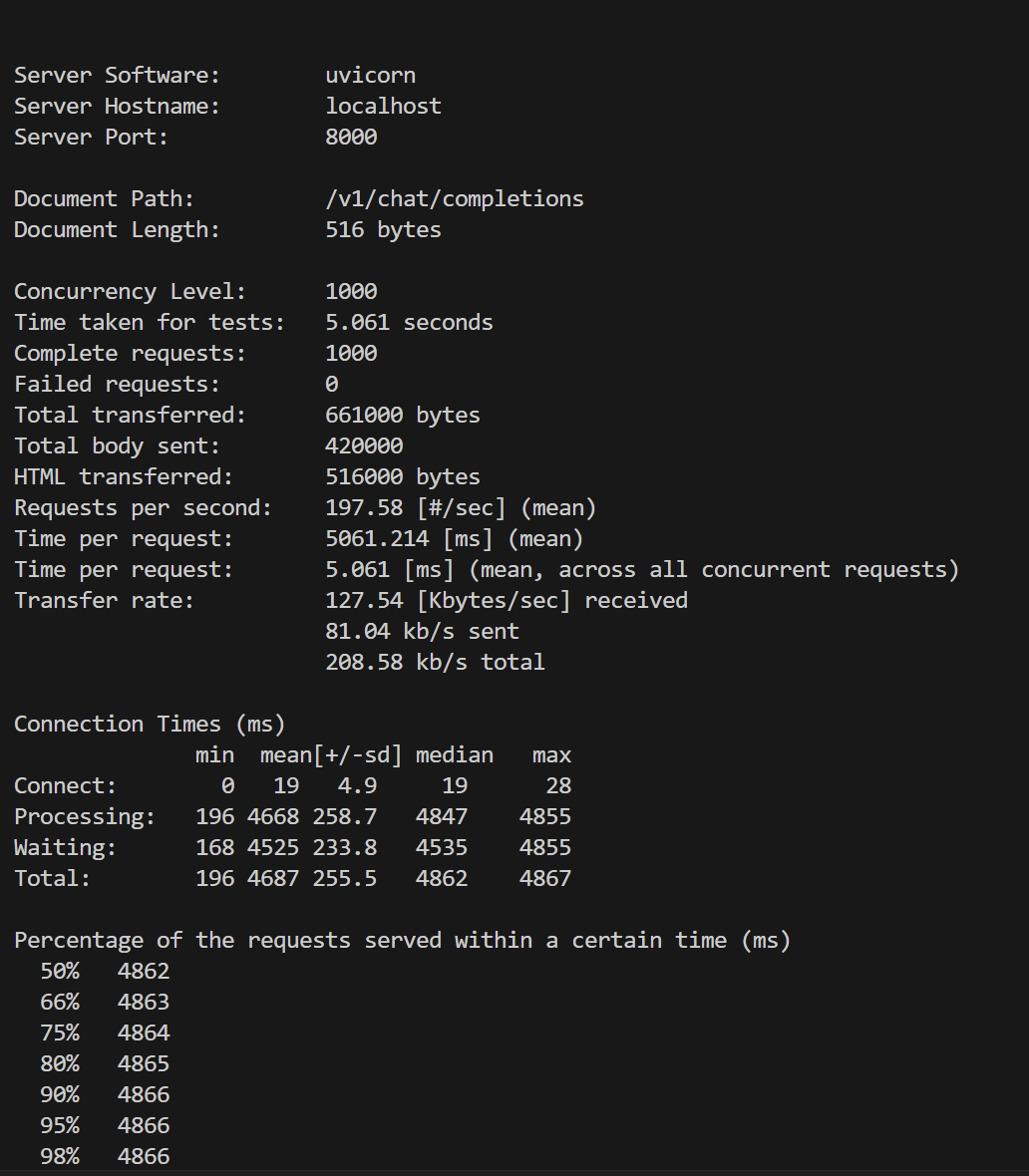
- 采用wrk测试
sudo apt-get install -y wrk
- post.lua
wrk.method = "POST"
wrk.body = [[{
"model": "TinyLlama/TinyLlama-1.1B-Chat-v1.0",
"messages":[{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Where is New York? Tell me in a single sentence."}],
"max_tokens": 32,
"temperature": 0
}]]
wrk.headers["Content-Type"] = "application/json"
执行
wrk -t12 -c1000 -d30s -s post.lua http://localhost:8000/v1/chat/completions
结果:
Running 30s test @ http://localhost:8000/v1/chat/completions
12 threads and 1000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 1.93s 35.39ms 1.99s 75.00%
Req/Sec 65.99 73.76 480.00 75.20%
5865 requests in 30.06s, 3.59MB read
Socket errors: connect 0, read 0, write 0, timeout 5677
Requests/sec: 195.09
Transfer/sec: 122.31KB
官方推荐的测试方法
TensorRT-LLM 基准测试 — TensorRT-LLM
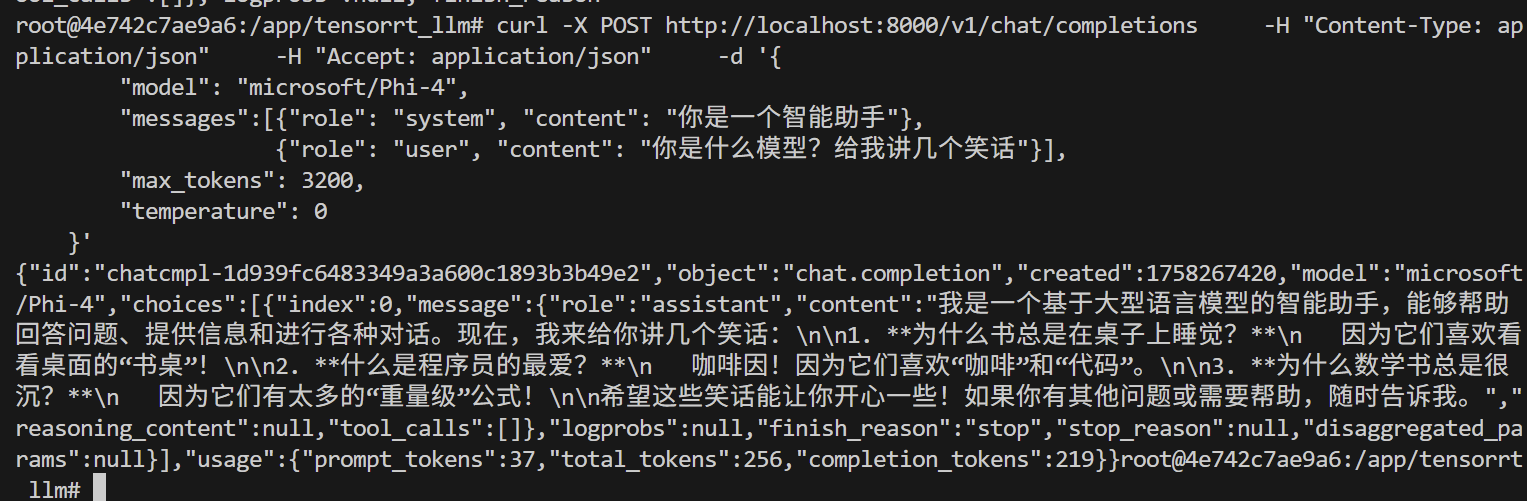
测试 phi4 服务
目前支持的大模型服务列表,选择对应版本查看
Supported Models — TensorRT-LLM
trtllm-serve "microsoft/Phi-4"