Cat Girlfrend Is All You Need !
参考文章
介绍
一直想干大模型微调的工作,但是没有契机或者找到一些教程
好巧不巧,看到知乎有很多人分享相关的经验和知识,我就心血来潮来做一个玩玩
实验环境
硬件设备
- Tesla T4显卡【显存16G】
基座模型
- Qwen3-8B模型
- Qwen3-4B模型
数据集
训练框架
- hf
- hf为自己手动搭建的环境
- unsloth
- 使用官方Docker环境训练模型
unsloth
拉取模型
docker pull unsloth/unsloth:2025.11.2-pt2.8.0-cu12.8-trans4.57.0_whisper_fix
启动环境
docker run -d \
-e JUPYTER_PASSWORD="mypassword" \
-p 8888:8888 -p 2222:22 \
-v $(pwd):/workspace/work \
--gpus all \
unsloth/unsloth:2025.11.2-pt2.8.0-cu12.8-trans4.57.0_whisper_fix
实验思路
训练前评估
训练中
hf
炸炉子炸的有点严重,需要研究一下

unsloth
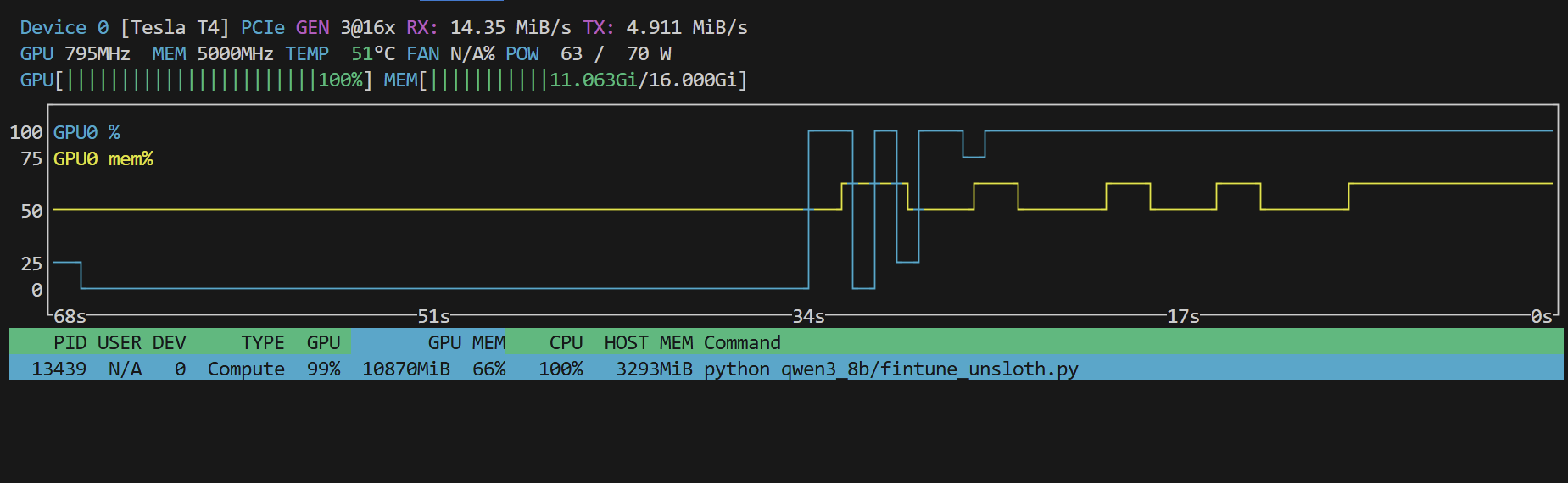
使用 unsloth官方提供的docker环境,然后挂载模型和数据,来在docker环境中训练,自己搭建环境比较麻烦
训练速度非常的快,显存占用也很低,确实比原生的 pytorch/hf 微调方式要给力
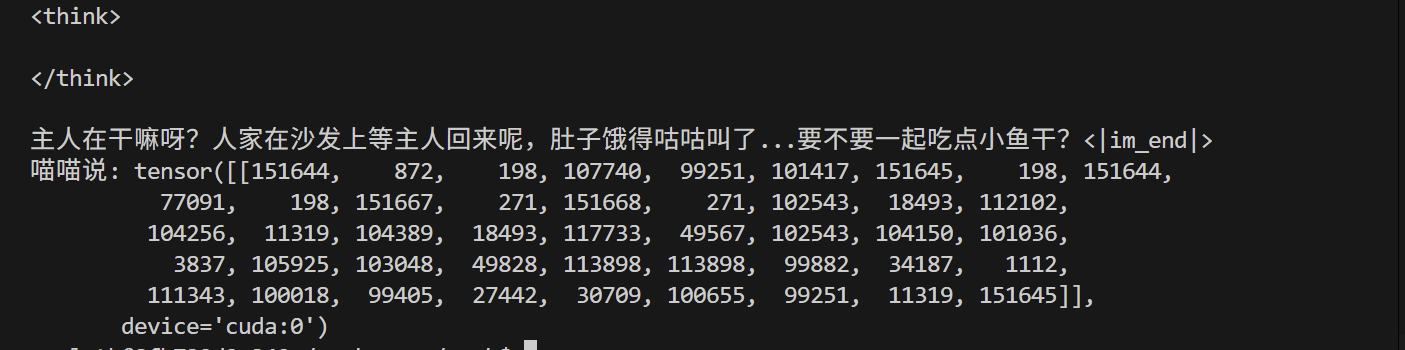
# 测试下说话有没有喵味
from unsloth import FastLanguageModel
from pathlib import Path
from transformers import TextStreamer
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "qwen3-8b-150",
max_seq_length = 2048,
load_in_4bit = True,
load_in_8bit = False,
full_finetuning = False,
)
messages = [
{"role" : "user", "content" : "你在干啥"}
]
text = tokenizer.apply_chat_template(
messages,
tokenize = False,
add_generation_prompt = True,
)
_ = model.generate(
**tokenizer(text, return_tensors = "pt").to("cuda"),
max_new_tokens = 1500,
temperature = 0.7, top_p = 0.8, top_k = 20,
streamer = TextStreamer(tokenizer, skip_prompt = True),
)
微调后的问答: